1200 participants, 194 teams, 2 rounds, lots of brain-racking, and constant lack of sleep. This is a one-sentence description of how we took part in a Hack4Retail hackathon for data science experts organized by McKinsey and Fozzy Group – and we passed it with flying colors, scoring first in this hackathon.
Hack4Retail was a challenging but inspiring experience for our ArtPeople team. And since it ended for us with the joys of victory, we’ve decided to share this experience and tell about the solutions that our hackathon team came up with in this blog post.
The hack. The team – Or what was it all about?
By its definition, a hackathon is an event that gathers a large number of people to take part in collaborative computer programming and creative problem-solving. It’s a great place to level up your knowledge and skills and get specific industry experience. And why not to win the prize and network with other professionals while taking part in the hackathon?
Hack4Retail was a hackathon for data scientists organized specifically for data scientists to solve real data science cases in retail. Among its organizers, there were the top management consulting firm, McKinsey and Company, and one of the largest Ukrainian trade industrial groups, Fozzy Group, so no wonder the organization was at the highest standards, and the participants dealt with truly challenging programming tasks.

Our ArtPeople team was composed of three data scientists, two from Intelliarts AI and one from SoftServe. Together we went through the two rounds – and enjoyed how unusual and demanding the tasks were. Let’s explore those cases in detail.
The first round – A weekend of two sleepless nights
Task 1: The first round was held online, from a Friday evening and till Sunday. All the 190+ teams were asked to predict e-commerce sales for specific geographical regions and products. For the sources for forecasting, we received a list of different stores from three different regions. Our main source was historical sales data that was dated from the beginning of 2021 and that covered around 300 products.
There was also a catch about this task. At least 80% of the data was zeros – a frequent case in the retail industry, and we had somehow to understand and clean this data if we wanted to create a reliable dataset.
Solution 1: This was the problem of regression, not classification, and we tried different approaches to solve it. One of them was to predict class 0/1 and whether there was a sale. If the sale was present, the model predicted value i.e. how many products were sold in units. Unfortunately, this approach didn’t work out.
Here’s another approach we tried and what worked better for us: if the product demand was moderate, then abruptly became zero, and returned to moderate, we removed those chunks of data and said that most likely, the product was not on the shelf. This way, we predicted values only for those data that were left. (What’s the most inspiring is that we’ve heard about this approach exactly from one of the data science hackathon’s speakers.)
As our algorithm, we chose CatBoostregressor, fine-tuned it a bit, and presented the results.
Moreover, we’ve understood that it was important not only to tune the algorithm but use business logic to generate new features.
We also focused on understanding the data instead of predicting the value only. Together, this approach gave us an opportunity to pass to the next round.
Can we apply this expertise in other industries?
Definitely yes. Forecast demand is a universal problem, and it helps businesses to make informed decisions and increase sales. Here are a couple of examples:
-
If we’re talking about manufacturing, businesses can apply forecast demand to prevent producing more products than those companies are able to sell. Another case is when a manufacturer wants to predict sales for a new product or in supply chain management to order the right number of materials.

-
In the automotive industry, forecast demand comes to the rescue to optimize inventory. Since this sector is constantly changing, forecast demand can save an automotive manufacturer from high maintenance costs in case of producing more products than demanded.
-
A better pricing model is the benefit of accurate forecasting in the insurance sector, such as insurance claims. In this example, forecast demand can help insurance companies and insurtechs to be one step ahead of their competitors.
The second round – 24 hours of non-stop Machine Learning
In the offline round, the 25 teams of finalists got two tasks, though these were connected to some extent. We’ll briefly discuss both of them.
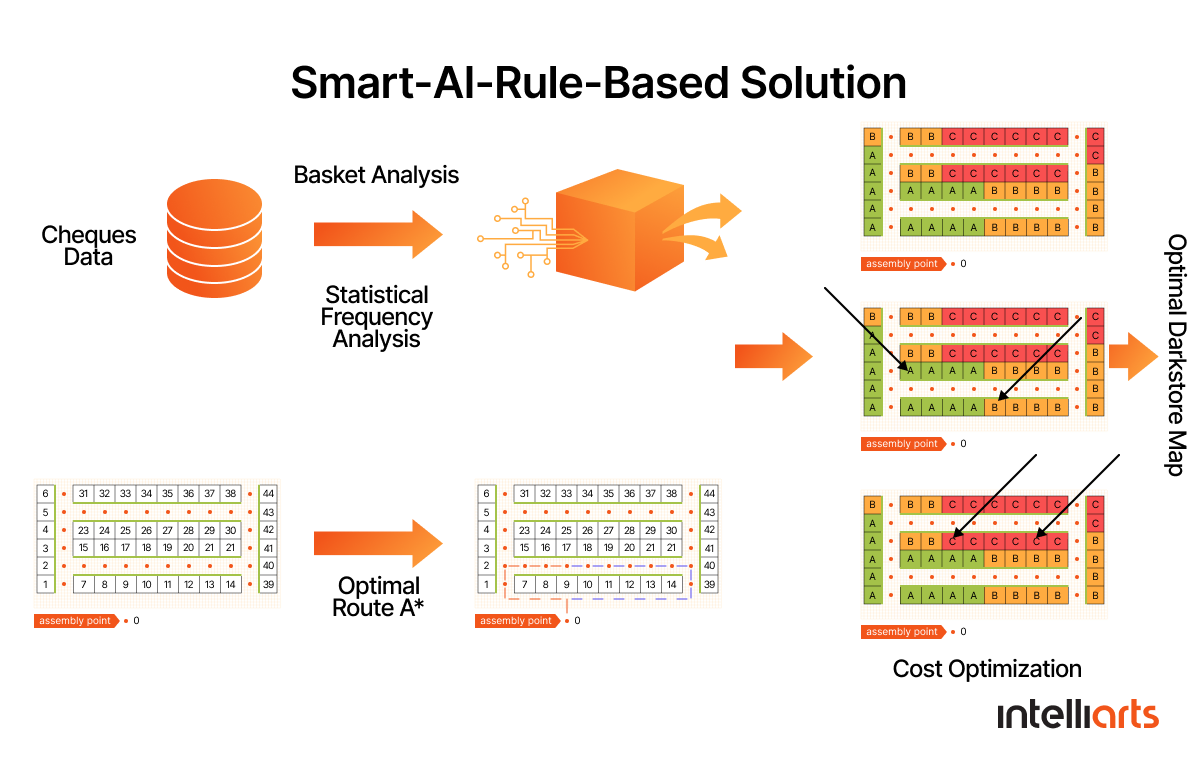
Task 2: Here the participants had to optimize the dark store map. Dark stores are so-called distribution centers that are close to visitors and are used instead for fulfillment operations. To solve this problem, the teams received a dark store map with 44 shelves with three levels and historical data of 5800 user orders (cheques) that we should use to locate the products more efficiently.
Solution 2: The classical machine learning approach wasn’t good for this problem because there was no 1 to 1 dependence for each cheque (one optimal location for one check). As the cheques were collected at one optimal placement, there was many to one dependence. We also didn’t see any sense in the classical optimization approach since it meant finding an optimal solution in specific data, which would not be robust enough.
Eventually, we’ve built the ML baseline model that provided the best optimizing results:
1. We took into consideration the frequency of buying products and placed the most popular ones the closest to the entrance.

2. After placing X number of the most popular products, we conducted a market basket analysis. Then, we counted the score for other products based on basket analysis i.e. how often they were bought together with the X products.
Eventually, it turned out that the frequency of purchase was not the only important factor.
Thanks to basket analysis, we were able to take into account mutually dependent product placement and formed conditional clusters of goods.
3. Additionally, we sifted through the cheques and chose those products that increased significantly the total time of collecting products for a single cheque according to our newly optimized dark store map. We moved those products one shelf closer to the product that we’ve just taken. This approach had to optimize the route even more.
Can we apply this expertise in other industries?
We can again. Although it may be less urgent as in retail, the problem of space optimization is present in other industries:
-
In manufacturing, we usually see lots of heavy, fixed, and complicated equipment. It takes lots of space and is difficult or even unable to move to another location. Machine learning can help manufacturers solve their storage space problems and optimize the facility’s existing footprint. Besides, good space planning is a good idea if a manufacturer wants to meet the value proposition as fast as possible.
-
Logistics space optimization also makes sense in automotive manufacturing. Here the finished products, as well as their parts, are too big, heavy, and sensitive to be moved around. So it’s great if the company finds out how to save space while also keeping its products in order and safe.
Task 3: The last task in the hackathon for data science engineers was based on the same optimization problem. However, this time, there were no limitations present in the dark store map optimization task, such as the constraints of having IDs instead of actual products or being unable to change the storage size.
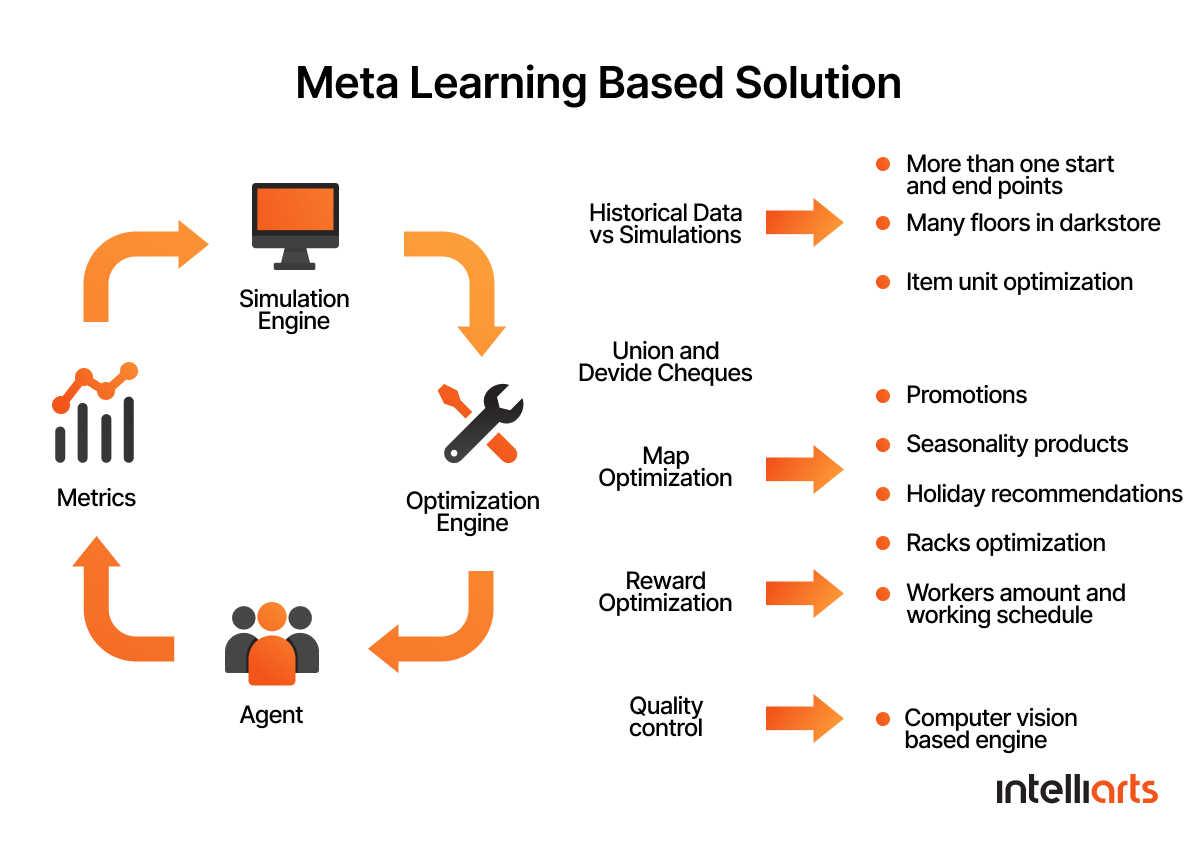
Solution 3: Here we proposed a Meta-Learning Based Solution, which meant building a complicated system that would combine the approaches of deep learning, reinforcement learning included, and classical optimization algorithms.
Based on this, we offered to build digital twins for each dark store, types of supply, and so on. By using these digital twins, retailers can run the mentioned ML algorithms and, hence, get more optimized solutions, such as in map optimization, reward optimization, or quality control.
Can we apply this expertise in other industries?
Sure yes. Defined as the visual representations of physical objects or processes, a digital twin is a breakthrough technology in many industries, which benefits with:
-
Intelligent recommendations
-
Remote monitoring and diagnostics
-
Analysis of root causes
-
The ability to self-tune
-
Process optimization
-
And others
To exemplify the use of digital twins in different industries, we can mention:
-
Smart manufacturing where digital twins can be used to check production optimization hypotheses and track metrics without implementing a solution in real life. For example, a vertical warehouse is a common solution in today’s manufacturing to save additional space. Digital twins can help a manufacturer check how suitable this solution is for a particular company without spending any resources on implementation.
-
The insurance sector where digital twins are still not popular yet can bring lots of value too. Using ML in underwriting, insurance companies, and insurtechs can achieve more accurate predictions of future risks due to the insights from real-time streaming data. Also, insurtechs can replicate the environment and detect potentially fraudulent claims with the help of digital twins.
-
Moreover, both manufacturers and insurers would benefit from digital twins in the context of some emergencies. Let’s take the Covid-19 example. Since this condition was impossible to predict, most predictive models were not efficient during the pandemic. However, a digital twin could have been useful in a situation like this since it’s an opportunity to simulate any circumstances and track how business metrics change.
Wrap up
Hack4Retail was one heck of experience, with hours of brainstorming, discussing, and implementing our vision with the help of data science and machine learning. We’ve got hands-on experience with realistic data, and although it was a new field of data science in retail for us to explore, we believe that we can use this newly obtained expertise in other domains as well, including manufacturing and insurance. Just contact us for our technology consulting to let us use this expertise in your business.
If you’re interested in implementing an ML-based project successfully, feel free to contact us. Intelliarts AI’s team is a one-stop source for your company that can accompany your business throughout your entire machine learning journey.