

Data preparation in ML is often overlooked compared to actual development, training, and testing processes. However, the quality of data is what lies at the heart of a successful ML model. In practice, most of the data that can be acquired is typically unprocessed and simply not suitable for ML in its raw form. That’s why proper data preparation is a must.
In this post, you’ll discover why machine learning needs data preparation. Besides, you’ll explore how to collect and how to prepare data for machine learning, followed by a review of challenges and best practices associated with this step. Additionally, you’ll find out about the tools that can be used to prepare data for machine learning.
Significance of data preparation
Data preparation in ML definitely shouldn’t be overlooked as a part of the ML development process. Here are some stats and numbers that prove this point:

According to the Garbage-in-Garbage-out (GIGO) rule, the end performance of any ML model essentially depends on the datasets it was trained on. Here are some of the necessary conditions of data intended to be used for ML development:
- Diversity
- Consistency
- Volume
- Quality
- Standardization
Naturally, data comes from various sources. It is often sourced both manually and automatically, sometimes, datasets even include machine-generated or synthetic data. It all boils down to the following fact:
Raw and unprocessed data typically doesn’t meet the sufficient conditions required for it to be suitable for machine learning purposes.
That’s exactly why data preparation is a step in ML that businesses should not avoid. The possible consequences of skipping on data preparation include:
- Reduced model accuracy
- Overfitting or underfitting
- Increased computation costs
- Model bias
- Scalability issues
- Misleading insights
Not having proper data is probably a top reason why an ML model is hard to build. In the worst-case scenario, it may be impossible to make an ML model show acceptable accuracy.
Key steps in data preparation
Data preparation in machine learning is a complex, multi-step process. It requires ML expertise and the usage of specialized software instruments. Here’s the basic basic steps for preparing data machine learning with examples:
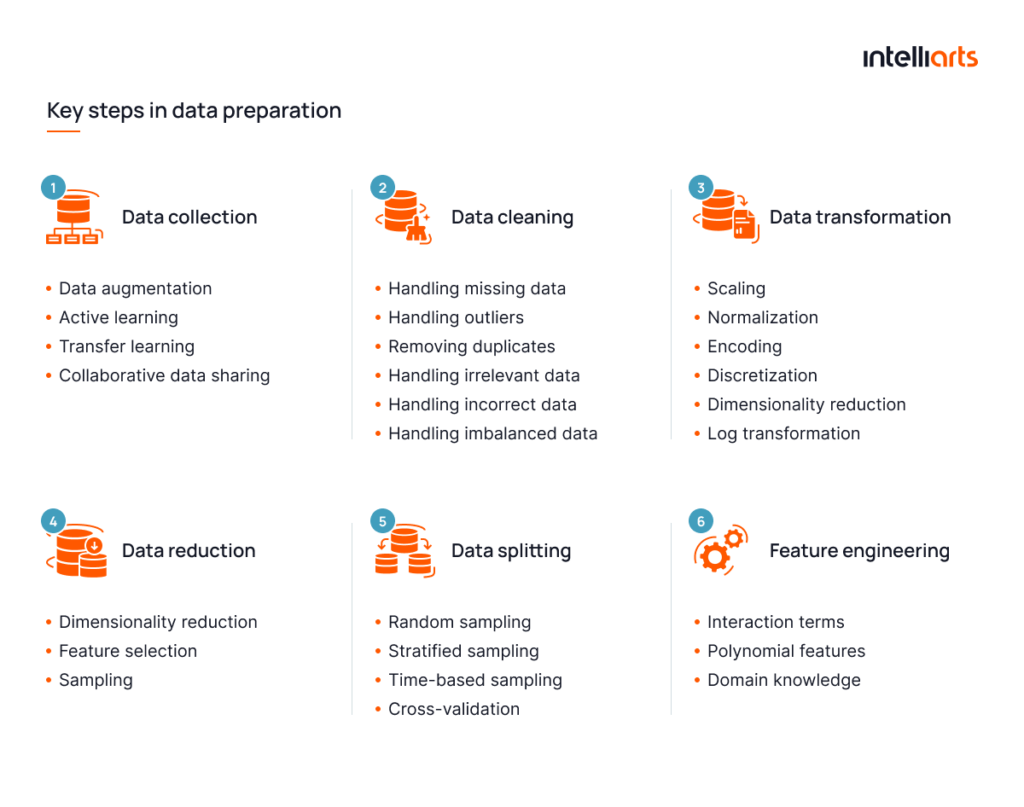
#1 Data collection
It implies gathering relevant data from various sources, such as databases, APIs, files, and online repositories. The first of steps in preparing data for machine learning encompasses matters of the type, volume, and quality of data. Here it’s necessary to ensure that the team has enough materials to execute an effective data preparation strategy.
Sources of data:
- Internal sources: Enterprise data warehouses, sales transactions, customer interactions.
- External sources: Public data sources like Kaggle, UCI Machine Learning Repository, and Google Dataset Search.
- Web scraping: Automated tools for extracting data from websites.
- Surveys: Collecting specific data points from target audiences.
Strategies for compensating for the lack of data:
- Data augmentation: Generating more data from existing samples.
- Active learning: Selecting informative data samples for labeling.
- Transfer learning: Using pre-trained models for related tasks.
- Collaborative data sharing: Working with other entities to share data.
Recommended tools: Python libraries (Pandas, Requests), ETL tools (Talend, Apache Nifi).
#2 Data cleaning
As stated previously, obtained data is nearly never suitable for ML. That’s why data cleaning or simply preparing raw data is required:
Data cleaning strategies:
- Handling missing data: Imputation, interpolation, deletion.
- Handling outliers: Removing, transforming, winsorizing, or treating them as a separate class.
- Removing duplicates: Using exact matching, fuzzy matching, and other techniques.
- Handling irrelevant data: Identifying and removing irrelevant data points.
- Handling incorrect data: Transforming or removing erroneous data points.
- Handling imbalanced data: Resampling, synthetic data generation, cost-sensitive learning, ensemble learning.
Recommended tools: Pandas, OpenRefine, Trifacta.
#3 Data transformation
Converting raw data into a suitable format for machine learning algorithms. This stage enhances algorithmic performance and accuracy.
Recommended techniques:
- Scaling: Transforming features to a specified range (e.g., 0 to 1) to balance their importance.
- Normalization: Adjusting data distribution for a more balanced feature comparison.
- Encoding: Converting categorical data into numerical format using techniques like one-hot encoding, ordinal encoding, and label encoding.
- Discretization: Transforming continuous variables into discrete categories.
- Dimensionality reduction: Limiting the number of features to reduce complexity using techniques like PCA (Principal Component Analysis) and LDA (Linear Discriminant Analysis).
- Log transformation: Applying a logarithmic function to skewed data for a more symmetric distribution.
Recommended tools: Scikit-learn, Pandas, Featuretools, Alteryx
#4 Data reduction
It often happens that the number of parameters in the data gathered is higher than necessary. For example, a survey may include responses that are not valid for preparing the data model. That’s why limiting the number of features or variables in a dataset is recommended. It helps preserve essential information while reducing complexity:
Recommended techniques:
- Dimensionality reduction: Techniques like Principal Component Analysis (PCA) and Linear Discriminant Analysis (LDA) reduce the number of features while retaining significant information.
- Feature selection: Methods like recursive feature elimination, mutual information, and chi-square tests select the most relevant features.
- Sampling: Reducing the dataset size by selecting a representative subset of data points.
Recommended tools: Scikit-learn, Pandas, KNIME, RapidMiner.
#5 Data splitting
Three types of datasets are necessary for training every single ML model:
- Training dataset. Used to train the model, helping it learn patterns and relationships between input features and target variables.
- Validation dataset. Used to tune model hyperparameters and evaluate performance during training to prevent overfitting.
- Testing dataset. Used to assess the final model’s performance on unseen data, ensuring it generalizes well to new data.
Dividing data into subsets is another necessary step. For training datasets, engineers use data of varying difficulty, from least to most complex. Validation datasets include specific cases, suitable for model fine tuning. Finally, a testing dataset is a suite of real-life numbers/ images/ documents, helping to actually measure the model’s accuracy.
Recommended approaches:
- Random sampling: Randomly splitting data, useful for large datasets.
- Stratified sampling: Ensuring subsets maintain the same distribution of class labels or characteristics, ideal for imbalanced datasets.
- Time-based sampling: Using historical data for training and future data for testing, applicable in time-series data.
- Cross-validation: Dividing data into multiple folds for training and testing to get a more accurate performance estimate (e.g., k-fold cross-validation).
Recommended tools: Scikit-learn, Pandas, TensorFlow.
#6 Feature engineering
Upon the training of a model, there’s often a need to scale it and reinforce it with additional functionalities. Creating new features or modifying existing ones to enhance model performance is known as feature engineering.
Recommended techniques:
- Interaction terms: Creating new features by combining existing ones.
- Polynomial features: Adding polynomial terms to capture nonlinear relationships.
- Domain knowledge: Leveraging expertise to create meaningful features.
Recommended tools: Featuretools, Pandas, Scikit-learn, Alteryx.
Read also about integrating predictive maintenance advantages into your manufacturing business.
Challenges and best practices
Data preparation in ML can happen to be a daunting and challenging task. In the next sections, the Intelliarts team distinguishes several common challenges and provides solutions to them. We also offer best practices for approaching machine learning data preparation:
Searching for the Right Data Science Partner?
Connect with Intelliarts to explore new opportunities.
Learn more
Common data preparation challenges
Here are some of the common data preparation difficulties that engineers face:
- Handling missing values
Missing values can lead to biased models or loss of valuable information, making the data less representative of real-world scenarios.
How to solve it: Use imputation methods, such as mean/mode substitution, or employ algorithms that handle missing data.
- Data imbalance
Missing values can lead to biased models or loss of valuable information, making the data less representative of real-world scenarios.
How to solve it: Techniques like oversampling the minority class, undersampling the majority class, or using synthetic data generation (e.g., SMOTE) can help balance the data.
- Noise and outliers
Noisy data and outliers can distort the true signal in the data, leading to misleading model outcomes and reduced accuracy.
How to solve it: Apply statistical methods to detect and remove outliers or use robust algorithms less sensitive to noise.
- Data integration from multiple sources
Combining data from various sources can introduce inconsistencies, errors, and redundancy, complicating the preparation process and potentially leading to inaccurate models.
How to solve it: Use data integration tools and techniques to ensure consistency, and perform thorough validation and cleaning during the integration process.
- Feature engineering
Creating relevant features from raw data is complex and requires deep domain knowledge to ensure that the features are meaningful and improve model performance.
How to solve it: Use automated feature engineering tools and collaborate with domain experts to create meaningful features that enhance model performance.
You may be additionally interested in exploring the role of data analytics in business in another of our blog posts.
Best practices for ensuring the high quality of prepared data

To ensure high-quality prepared data, verify that all samples accurately represent the business logic that is not covered. Also, ensure that samples are free of inconsistencies, such as duplicate samples with different labels. Try to include as many meaningful hand-generated features as possible to make the model job “easier.”
Aside from the solution to common challenges mentioned in the section above, there’s a range of best practices that the Intelliarts team adheres to:
- Thorough data cleaning. Regularly audit your dataset for anomalies and use automated data cleaning tools to maintain high standards of data quality.
- Data validation and consistency checks. Implement validation rules and consistency checks during data entry and data integration processes to catch and correct inconsistencies early.
- Usage of standardized formats and coding schemes. Establish and adhere to data standards and conventions, such as ISO date formats and standardized codes for categorical variables, to facilitate easier data integration and analysis.
- Regular data profiling and monitoring. Use data profiling tools to regularly monitor data quality metrics, such as completeness, accuracy, and uniqueness, and take corrective actions when deviations are detected.
- Collaboration with domain experts. Don’t hesitate to involve domain experts in the data preparation process to provide insights into data relevance, context, and appropriate feature engineering techniques.
- Documentation and metadata management. Keep comprehensive records of data sources, processing steps, and quality assessments to streamline how to trace ML data sets to ML requirements. Besides, metadata management tools must be constantly used to ensure the traceability of data preparation in machine learning.
Data preparation success stories of Intelliarts
Here are brief insights into several out of the many data preparation-related cases the Intelliarts team had:
Predictive lead scoring for insurance company
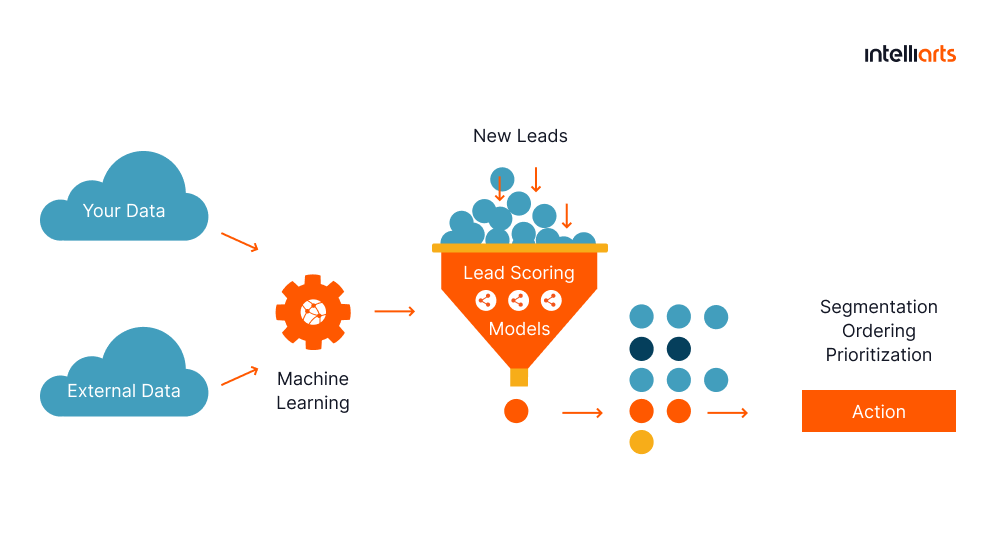
The Intelliarts customer, a midsize insurance company, reached out to us with the request to simplify their labor-intensive and restricted traditional lead scoring process.
In this machine learning in insurance case, we created a predictive lead scoring model able to forecast how likely the lead would buy a policy. With this custom insurance software, insurance agents can focus their efforts on the most prospective clients. From a data preparation perspective, our team of data scientists had to kick off work on the project with data collection. We gathered and processed information for customer behavior, quotes, demographics, property, and contacts, before proceeding with the development.
The final lead scoring software successfully cut off approximately 6% of non-efficient leads, which resulted in a 1.5% profit increase for Intelliarts’ customer. Now, the company groups the clients by the probability of sales success. The group with an 80% probability converts 3.5 times more often than the average industry conversion.
Explore the predictive lead scoring for insurance company case in more detail.
ML-powered list stacking and predictive modeling for the real estate business
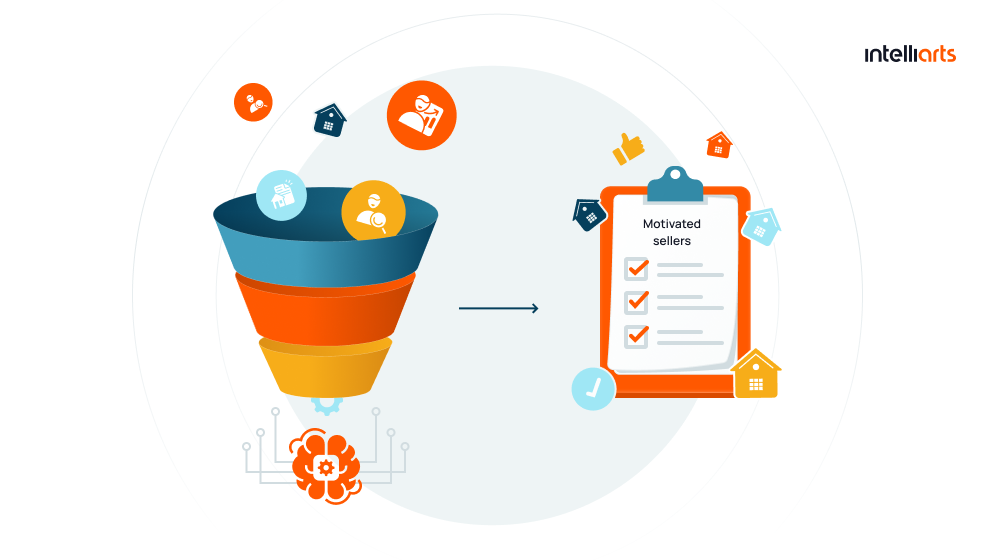
The Intelliarts customer, an established real estate brokerage, contacted us with the request that we assist them in making better use of their extensive real estate market and homeowner data. The purpose was to anticipate which homeowners are most likely to sell their homes in order to increase the productivity of real estate brokers.
In this project, we developed a complicated ML solution composed of realtor and investor ML models. In the process of model training, we dealt with diverse data which consisted of 900+ property characteristics, 400 attributes of demographic data, and skip tracing data. The training was conducted using a training dataset in machine learning consisting of 60 million data records. Now the end solution is updated monthly in batches of 100-200 GB of data.
The final system successfully identifies the most motivated sellers with an accuracy of more than 70%, which is impressive for such a technology application. It increased the Intelliarts customer’s monthly revenue by 600%.
Explore the ML-power list staking and predictive modeling case in more detail.
Tools and technologies
While data preparation software instruments and technologies are many, the Intelliarts team would like to suggest using the following several options, as they are well-tried and tested:
#1 Pandas
Pandas is an open-source data manipulation and analysis library for Python, providing data structures and functions needed to work with structured data.
- Key Features: Data cleaning, transformation, aggregation, and visualization.
- Use case: Handling and manipulating large datasets, especially in CSV, Excel, and SQL formats.
Scikit-learn
Scikit-learn is a robust machine learning library for Python, offering simple and efficient tools for data analysis and modeling.
- Key features: Preprocessing modules for handling missing values, scaling, normalization, and encoding categorical variables.
- Use case: Preprocessing data and building machine learning models in a streamlined manner.
DataRobot
DataRobot is an automated machine learning platform that accelerates the process of building and deploying predictive models.
- Key features: Automated data cleaning, feature engineering, model selection, and hyperparameter tuning.
- Use case: Quickly developing high-quality machine learning models with minimal manual intervention.
Apache Spark
Apache Spark is an open-source unified analytics engine for big data processing, with built-in modules for streaming, SQL, machine learning, and graph processing.
- Key Features: Distributed data processing, in-memory computing, and support for various data sources.
- Use Case: Optimal for handling large-scale data preparation tasks in a distributed computing environment.
Alteryx
Alteryx is a data preparation and blending tool that enables data analysts to prepare datasets for machine learning algorithms, blend, and analyze data from various sources.
- Key features: Drag-and-drop interface, extensive library of pre-built tools, and seamless integration with popular data sources and analytics platforms.
- Use case: Data analysts and business users looking to streamline data preparation and analytics workflows.
KNIME
KNIME is an open-source data analytics, reporting, and integration platform.
- Key features: Visual workflow editor, extensive range of pre-built nodes for data manipulation, and integration with machine learning libraries.
- Use case: Creating end-to-end data science workflows, from data preparation to model deployment.
Looking for a trusted provider of AI and ML development services? Reach out to the Intelliarts team.
Future trends in data preparation
Let’s finalize the post by reviewing some of the possible routes of the evolution of successful data preparation in machine learning projects:
- Automated data preparation. We can expect increased usage of AI-based solutions to help automate data cleaning, transformation, and feature engineering processes. It will reduce manual effort and speed up the process.
- Augmented analytics. Evaluating the ready data and planning for changes in data preparation is still mostly done manually. Leveraging AI-driven insights and recommendations to assist users in data preparation tasks can be another potential improvement. This also will empower non-experts to prepare complex data.
- Enhanced data integration. In business, data sources and types are many. Integration of diverse data from all the available sources potentially will bring better outcomes of data analysis.
- Further scalability and performance optimization. There’s a need for tools that will be capable of handling large-scale datasets efficiently. This matter is deeply connected to leveraging cloud and distributed computing. If implemented, this will result in better potential for using complex and large-scale ML applications.
Hopefully, over the span of the next few decades, approaches to data preparation in ML will become advanced enough to relieve most of the burden of ML engineers.
Final take
Data preparation in ML helps to create high-quality datasets that improve model performance and accuracy. By following best practices, addressing common challenges, and leveraging advanced tools, organizations can streamline this process. As the field evolves, automation and augmented analytics will further enhance data preparation, empowering even non-experts to handle complex tasks. For instance, vehicle damage detection models rely on well-prepared datasets to accurately assess and classify damage, improving the precision and speed of insurance claim processing.
Partnering with a big data consulting firm can provide the expertise and resources needed to efficiently manage data preparation and integrate ML-based solutions. Consider entrusting data preparation and ML-based solution development to Intelliarts. With more than 24 years of experience in the market and proven expertise, our engineering team can address any of your ML development needs with flying colors.
FAQ
1. How to handle missing values during data preparation?
Handling missing values during data preparation involves imputation, removal, or using algorithms that handle missing data. Tools like pandas and Scikit-learn offer efficient data preparation tools for machine learning to address this issue.
2. Can data preparation impact machine learning model outcomes?
Yes, data preparation significantly impacts machine learning model outcomes. Steps for preparing data for a prediction model include cleaning, normalizing, and transforming data, ans they are crucial for model accuracy and performance.
3. Is data preparation a one-time process?
No, data preparation is an iterative process. As new data is collected, continuous refinement and re-preparing data for machine learning are necessary to maintain model performance.









