

In machine learning (ML), data preprocessing is one of the essential steps that largely impact the outcomes of the development and usage of any created ML model. So, for the management of tech companies and ML enthusiasts, having a proper insight into nuances and best practices of data preprocessing is essential for optimal project planning and execution.
The ML market size is expected to grow at a CAGR of 17.15% up to 2030. It clearly indicates the strong tendency of companies worldwide to join digital transformation, investing in ML-based solutions to diverse business needs. This directly implies the growing importance of solid data preprocessing.
In this post, you’ll discover more about data preprocessing and its actual importance. Besides, you’ll learn 6 best practices for data preprocessing, which are based on the vast experience of Intelliarts with pre-processing diverse data for various projects such as DDMR data marketplace or analyzing IoT data for OptiMEAS. Additionally, you’ll review real-life case studies of successful data preprocessing.

What is preprocessing in machine learning and why it’s due
Preprocessing in machine learning is the preparation of data through cleaning, normalization, and feature engineering to improve model performance and accuracy.
You may wonder why you even need data preprocessing when you already have real-life, seemingly suitable data. Here are the reasons why training and then utilizing a model can bring results that are far from optimal if the preprocessing step is excluded:
- Lack of sufficient data
- Poor quality data
- Overfitting
- Underfitting
- Bad choice of algorithm
- Hyperparameter tuning
- Bias in the dataset
Basically, for these and possibly other reasons, you will not be able to build a model that shows expected performance in actual business processes. So, the data preprocessing step is rather unavoidable.
You can see what place data preprocessing occupies in the data preparation process in the infographic below:
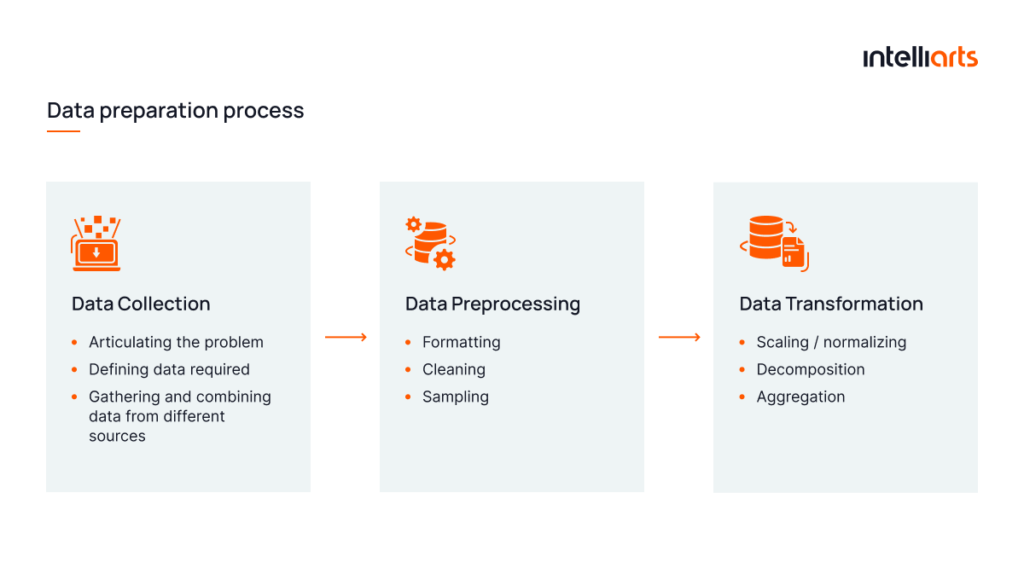
Additional information on machine learning advantages can be found in another Intelliarts blog post.
Importance of Preprocessing in Machine Learning
Let’s take a look at three main values that preprocessing has to offer to the overall data preparation procedure crucial for machine learning development:
Impact on model performance
Cleaning and preparing the data beforehand ensures the models are trained on high-quality, relevant data. This process includes:
- Normalization. Scaling data to a uniform range.
- Feature encoding. Transforming categorical data into a machine-readable format.
- Handling missing values. Filling in or omitting gaps in data to prevent bias and improve model reliability.
Accurate preprocessing can significantly increase the accuracy of the model while reducing the time and computational resources needed for training.
Avoiding garbage in, garbage out (GIGO)
The principle of “garbage in, garbage out” is particularly relevant in the context of machine learning. Without proper preprocessing, even the most sophisticated algorithms can yield inaccurate or irrelevant results. The main idea here:
The inaccuracies in real-life ML cases often result from inadequate training datasets because machine learning models learn patterns from the data they are fed.
If the data is incomplete, inconsistent, or laden with errors, the models will internalize these flaws, leading to poor performance. Preprocessing ensures the data is clean and consistent, laying a solid foundation for the models to learn from.
Enhancing data quality
Preprocessing directly enhances the quality of data, making it more suitable for machine learning models. Possible measures here are:
- Noise reduction techniques. Removing irrelevant or redundant features to focus the model’s attention on the most informative aspects of data.
- Data transformation. Applying mathematical transformations like log or square root to stabilize variances.
- Encoding categorical variables. Converting categorical data into numerical format for model compatibility.
- Dimensionality reduction. Techniques like Principal Component Analysis (PCA) reduce data dimensionality.
- Data sampling. Balancing class distribution in imbalanced datasets.
By improving data quality, preprocessing ensures that machine learning models can extract the most value from data, leading to more accurate and generalizable insights.
If you’re interested in data processing and machine learning, you may also be interested in exploring the post on the topic of big data and AI.
Top 6 best practices for data preprocessing in machine learning
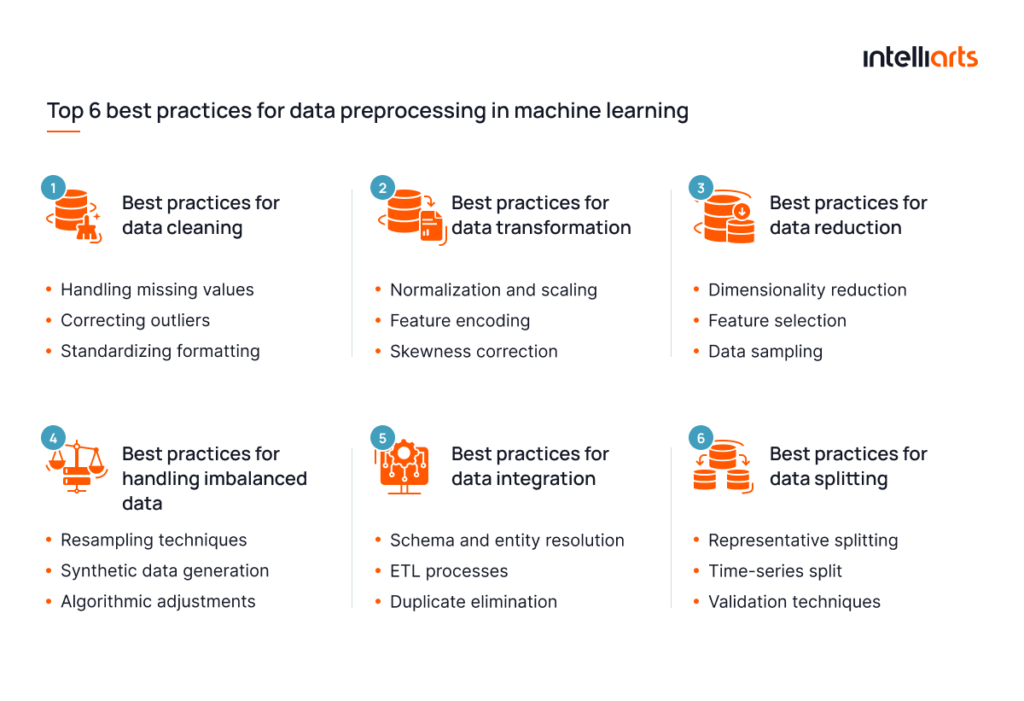
Now when you’re aware of what preprocessing serves for, let’s find out what best practices for ML development are there to handle one or another data preprocessing technique in a proper way:
#1 Data cleaning
Proper data cleaning is foundational to any machine learning project, as it ensures the dataset is free of errors and inconsistencies that could skew results. Here is what the Intelliarts team of big data engineers has to advise you:
- Handling missing values: Impute missing values using statistical methods (mean, median) for numerical data or mode for categorical data, or remove rows/columns with excessive missing values to maintain data integrity.
- Correcting outliers: Identify outliers through statistical tests or visualization techniques and correct them using capping, transformation, or removal to prevent distortion of the dataset.
- Standardizing formatting: Ensure consistent data formats across the dataset, including date formats, capitalization, and units of measurement, to avoid discrepancies during analysis.
Conclusively, clean data is the bedrock of reliable machine learning models, making meticulous cleaning an indispensable step.
#2 Data transformation
Transforming data into a format that can be easily analyzed is vital for machine learning algorithms to perform optimally. Here are the practices for every data transformation technique:
- Normalization and scaling: Apply normalization (e.g., Min-Max scaling) or standardization (Z-score normalization) to scale features, ensuring no attribute dominates others due to its scale.
- Feature encoding: Convert categorical data into numerical formats using one-hot or label encoding, allowing algorithms to process and learn from such data effectively.
- Skewness correction: Apply logarithmic, square root, or Box-Cox transformations to reduce skewness in data distributions, enhancing model accuracy.
Effective data transformation facilitates the smooth and efficient training of machine learning models by making the data more amenable for analysis.
#3 Data reduction
Reducing the dimensionality of the dataset can significantly speed up training times and improve model performance by eliminating redundant features.
- Dimensionality reduction: Employ techniques like PCA to reduce the number of features while retaining most of the variability in the data.
- Feature selection: Use methods such as mutual information, chi-square test, or feature importance scores to keep only the most relevant features.
- Data sampling: In cases of large datasets, use sampling methods to create a manageable subset that accurately represents the whole dataset.
Data reduction should not only simplify the model but also enhance its interpretability and reduce the risk of overfitting.
Looking for a trusted expert in machine learning and big data? Drop engineers from Intelliarts a line, and let’s discuss opportunities for your business.

#4 Handling imbalanced data
Imbalanced datasets can lead to biased models that perform poorly on minority classes, making it crucial to address this imbalance.
- Resampling techniques: Balance the dataset by either oversampling the minority class or undersampling the majority class to prevent model bias.
- Synthetic data generation: Tools like SMOTE can generate synthetic samples for the minority class, enhancing the diversity of data available for model training.
- Algorithmic adjustments: Opt for algorithms that are less sensitive to class imbalance or adjust the algorithm’s weights to make it more attentive to the minority class.
Addressing data imbalance is key for developing fair and accurate models, especially in applications where minority class predictions are critical.
#5 Data integration
Combining data from various sources can enrich the dataset but requires careful handling to ensure consistency and quality.
- Schema and entity resolution: Reconcile differences in data structure and entity representation across sources to prevent conflicts.
- ETL processes: Use extract, transform, and load techniques to clean, merge, and integrate data from different sources seamlessly.
- Duplicate elimination: Identify and remove duplicate records to maintain the integrity of the dataset, preventing skewed analysis and results.
Effective data integration provides a comprehensive view of the dataset, enabling more nuanced insights and predictions from machine learning models.
#6 Data splitting
Correctly splitting the data into training, validation, and testing sets is crucial for assessing the model’s performance accurately.
- Representative splitting: Ensure each split reflects the overall distribution of the dataset, including stratification for classification problems to maintain class ratios.
- Time-series split: For time-dependent data, use chronological splits to preserve the temporal order and avoid future data leakage into the training set.
- Validation techniques: Employ techniques like cross-validation to utilize the dataset efficiently for training and validation, ensuring robust model evaluation.
Proper data splitting strategies are essential for validating model performance and generalizability to unseen data, thereby enhancing the reliability of machine learning applications.
Intelliarts case studies
Let’s take a look at some of Intelliarts’ success stories related to data preprocessing in machine learning:
Improving lead quality and insurance agent efficiency

The customer requested help detecting leads who are more likely to purchase a health insurance policy. They provided their vast databases for us for this purpose.
The Intelliarts, as an insurance software development company, created an ML-based solution that preprocesses data and then utilizes it to determine leads that are more prepared to make a purchase based on multiple factors like demographics, region, age, gender, and more.
The application of machine learning for insurance by Intelliarts team contributed to a 5% increase in the customer’s lead quality and increased agent efficiency by 3%.
Discover more about the improving lead quality case study.
Processing and analyzing IoT data for OptiMEAS
The customer’s request was to help utilize the data they gather from their IoT devices more effectively.
To help the customer make use of the vast IoT data it gathers, Intelliarts built a fully-fledged data processing pipeline. The end solution can collect, analyze, process, and visualize big data effectively.
With the help of the data pipeline we built, OptiMEAS can now transform its vast data into actionable insights and make informed decisions.
Discover more about the OptiMEAS case study.
Building a B2B DEI-compliant job sourcing platform for ProvenBase

The customer’s request was to help them establish ML-based processes for automated CV parsing and candidate searching and scoring.
To help the customer, Intelliarts created an ML solution composed of several trained ML models. One of them is an AI-based job description analyzer that can derive key information for sourced candidates to be used for scoring later.
Our solution enabled automated candidate profile sourcing and candidate profile matching. The end model shows over 90% accuracy.
Discover more about the ProvenBase case study.
Final take
It’s impossible to go without data preprocessing in nearly any ML development project. Successful gathering and processing of vast amounts of data significantly increases the chance of building a working solution after a minimum number of iterations and with the best operational outcomes on real-life data. Following best practices in data preprocessing is how you maximize the value of the effort put into preparing your data.
Having the right tech partner for running your ML project is half the battle. Consider reaching out to expert data science and ML engineers from Intelliarts. With 24+ years of experience, hundreds of projects successfully delivered, and substantial experience with businesses from numerous industries, we are ready, willing, and able to contribute to your best project.
Skilled ML experts at your service
We use advanced machine learning to drive innovation for your business
Talk to us
FAQ
1. What are the major steps of data preprocessing?
Major data preprocessing steps include data cleaning, integration, transformation, reduction, and feature selection/extraction.
2. What are the benefits of data processing in machine learning?
The benefits of preprocessing data in machine learning encompass improved accuracy, enhanced data quality, reduced complexity, better handling of missing values/outliers, and improved model interpretability.
3. What is the importance of data preprocessing?
The importance of data preprocessing lies in ensuring high-quality data for accurate models, enhancing model performance, enabling efficient learning, and achieving reliable and interpretable machine learning outcomes.









