

Data extraction from documents is a real goldmine for businesses across different domains. Client agreements, contracts, reports, financial statements, or regulatory compliances — all this gets documented in everyday business operations. Unfortunately, at least 80% of this data is collected and stored in unstructured formats, PDFs included, complicating access and affecting decision-making processes.
With strong machine learning and data engineering expertise, Intelliarts can help companies with automating PDF data extraction in a matter of seconds. By leveraging machine learning (ML), professionals can quickly access critical data without manually sifting through thousands of pages.
Benefits of automating data extraction from PDFs
Information extraction fits the wider concept of text mining, i.e. an essentially AI technique used to convert raw, unstructured data into structured one. The purpose of all this is pretty straightforward: a computer understands only structured information, which makes text mining so critical in many industries, from finances to law to healthcare to insurance.
In text mining, we can then talk about data extraction. Its idea is to retrieve useful info from a large body of text by gaining an understanding of its entities, attributes, and relationships. How is this possible? Naturally, with the help of machine learning, you can do automated PDF data extraction. ML algorithms automatically scan the information and retrieve the core words or phrases from unstructured text.

Here is the simplest example for you: the insurance company gets a request for dog insurance. During automated claims processing, an insurance agent looks for this specific case and types “dog insurance” keywords into the ML-based system. Instead of scanning through hundreds of pages, the agent will have to go through only those tens that the system will provide to them. The system can even highlight the areas where it’s mentioned “dog insurance”.
Explore our Insurance Software Development Services.
As more data is not only stored but gets collected in digital format, companies can use ML-based automated PDF data extraction to their advantage. Specifically, businesses can turn volumes of the info they store into useful data, extract the information seamlessly, and improve operational efficiency.
Let’s list specific benefits of extracting data from PDF using machine learning:
- Optimized document processing. ML algorithms can automatically extract critical information, leading to enhanced operational efficiency. Unstructured documents will be handled faster, speeding up business processes and reducing costs by at least 40-60%, as mentioned in the Capgemini report.
- Reduced manual data extraction. With ML, professionals no longer need to manually search for information by scanning through documents such as reports, contracts, and agreements. Instead, they can obtain data seamlessly and in a format ready for further integration into the company’s document management system.
- Increased accuracy. ML technology analyzes the correlative and causal allocation of data, scanning the environment for more accurate results. It identifies synonyms and related words, enhancing data extraction accuracy. For example, if you’re looking for a “dog,” an ML model will likely identify words like “pet” or “husky.” Additionally, the self-learning nature of ML means the more you use an ML data extraction solution, the more it “learns,” leading to improved efficiency over time..
- Improved customer experience. Faster and more accurate document handling can significantly enhance customer satisfaction. By streamlining processes and reducing errors, ML-based data extraction can serve as a strategic tool to differentiate your business in the market and boost competitive advantage.
- Better decision-making. ML-driven data extraction provides faster access to critical data, allowing businesses to make informed decisions more quickly. With accurate and timely information at their fingertips, businesses can respond to market changes, customer needs, and operational challenges more effectively.


Common challenges in PDF data extraction
After we discussed the benefits of ML-powered data extraction, it’s time to talk about common challenges that companies meet on their way to automation. Businesses may find applying AI to extract data from documents challenging because of:
- The need for quality data: To be able to automate the data extraction process, you’ll need enough quality data to feed into your analytics. Poor data causes flawed conclusions and, what’s worse, may lead to revenue loss and negative effects on the business’s reputation.
- Massive data volumes: Businesses accumulate amounts of data over time through diverse data sources, and a large part of this data is stored unstructured. As a result, the problem arises of how to store and manage this data in a productive way to make use of it later.
- Dealing with data extraction in bulk: Handling PDF data extraction in bulk could put an excessive load on your system, resulting in repeated system errors, delays, or extra costs.
- Integration with other systems: A new data extraction tool can appear incompatible with the existing systems, which can create another obstacle to smooth workflows. This issue is especially relevant if a company is using multiple and/or unusual formats.
How to automate data extraction from PDF
Machine learning is only one among other ways of automating data extraction. To see the bigger picture, let’s compare ML-based data extraction to other methods:
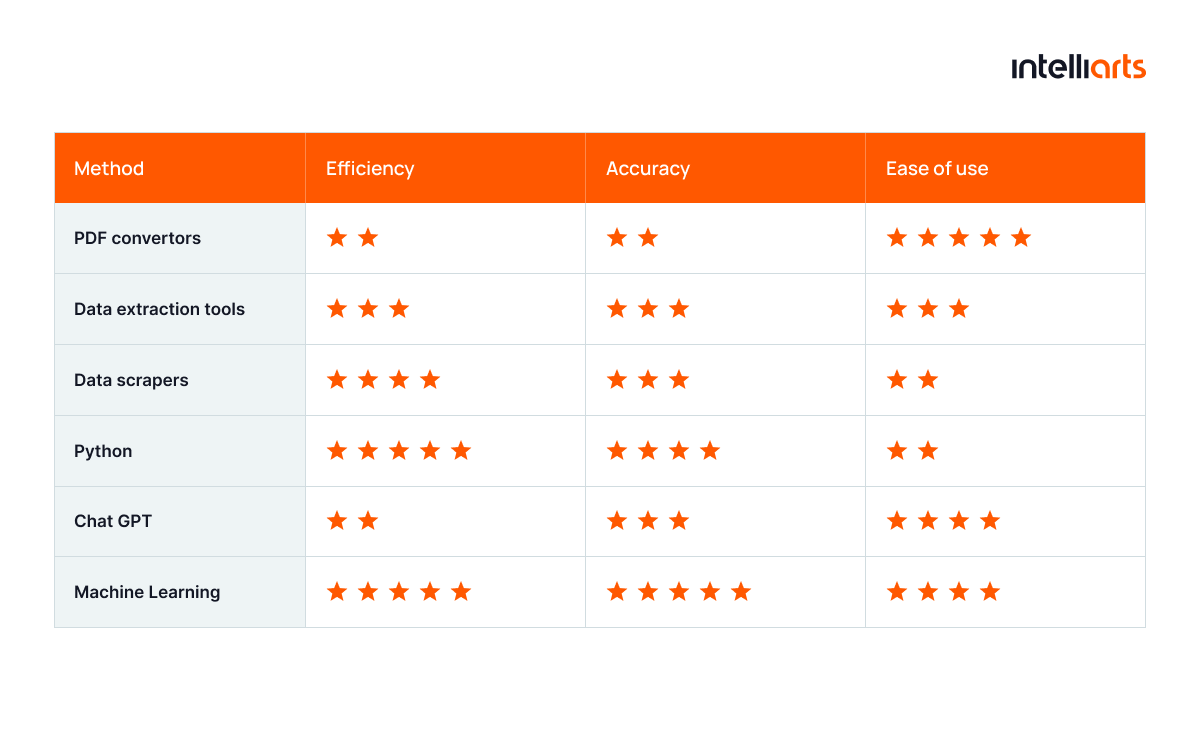
So, we can automate PDF data extraction with the help of:
1. PDF convertors
PDF converters are widely used tools for transforming PDF documents into various formats such as Word, Excel, or plain text. While PDF converters can be a helpful tool for basic document transformation needs, they fall short in handling complex data extraction tasks that require high accuracy and contextual understanding.
Pros
- Ease of use
- Versatility
- Quick processing
Cons
- Limited accuracy
- Lack of contextual understanding
- Manual corrections
2. PDF data extraction tools
PDF data extractors are specialized software designed to automatically extract structured data from PDFs. They usually provide a simplistic UI and no need for coding to extract documents. These tools do offer better accuracy and efficiency as compared to PDF convertors but could be a worthwhile investment because of their complexity.
Pros
- Accuracy and efficiency
- Integration
Cons
- High costs
- Technical expertise required
- Initial setup time
3. PDF data scrapers
PDF data scrapers are tools designed to extract data from PDF automatically by identifying and capturing relevant information. These tools are particularly useful for handling large volumes of unstructured data. At the same time, data scrapers come with challenges such as complexity and maintenance requirements so they function correctly as document formats change.
Pros
- Ability to configure to extract specific data fields
- Adaptability to various document layouts and structures
- High scalability
Cons
- Complex setup
- Variable accuracy depending on the quality and consistency of documents
- Complex setup
- Maintenance and regular updates required
- High costs
4. PDF data extraction using Python
Using Python, as a high-level programming language, for PDF data extraction involves leveraging various libraries and tools to automate information retrieval. This approach offers flexibility and cost-effectiveness, making it a powerful tool for businesses with the right technical resources. However, it requires a certain level of expertise and ongoing maintenance to maximize its effectiveness.
Pros
- Flexibility because of a variety of libraries such as PyPDF2, PDFMiner, and PyMuPDF that can be tailored to specific data extraction needs
- Ability to handle large volumes of documents
- Cost-effectiveness because of open-source libraries
- Integration with other systems and databases
Cons
- Technical expertise required
- Complex setup
- Maintenance and regular updates required
- Variable accuracy depending on the quality of documents and robustness of the implemented script
5. PDF data extraction using ChatGPT
Alternatively, you can ask ChatGPT to help with data extraction. This way, the tool will provide you with a series of Python codes so you don’t need any specialized knowledge. Tailor your prompts based on the specific data you need to extract from the PDF. For instance, you can focus on identifying key points in a contract or summarizing reports.
Pros
- Ease of use
- Contextual understanding
- Customization
- Advanced capabilities if you’re using GPT-4 Vision or other paid versions of ChatGPT
Cons
- Initial setup
- High costs
- Privacy concerns
6. ML-powered data extraction
Machine learning (ML) has significantly improved the efficiency and accuracy of data extraction from PDF files. As mentioned earlier, by leveraging ML algorithms, businesses can automate the extraction process and gain valuable insights from their documents.
Pros
- High efficiency and accuracy
- Scalability
- Real-time processing
- Consistency
- Adaptability
Cons
- Technical expertise required
- Initial setup and training
- High costs
Read also about AI-based object counter solution by Intelliarts.
What’s going on under the hood?
In the world of machine learning, we’re speaking about the optical character recognition (OCR) task when we say that we want to extract text from images, PDFs included. This is how computers can make sense of texts and make them machine-readable.
The common scenario for the use of OCR is when you have to extract unstructured data from PDFs. On the one hand, printed documents like PDFs are structured, which makes them easy to parse. Besides, there are many tools developed specifically for this type of OCR task since it’s quite popular.
You might also be interested in reading about analyzing images to assess car damage with an AI vehicle damage inspection.
On the other hand, the very nature of the PDF document makes it difficult for text extraction, since it was developed with the goal to share the information between platforms easily while preserving both content and layout of the document. This explains why PDFs are usually so difficult to edit. The OCR task here is complicated, also depending on the type of information needed. Is it just text? Or does the position, fonts, etc. also matter? Everything is possible with data extraction in machine learning. However, every extra layer of information requires more professionalism from your data consulting scientists.
Strategies for OCR
From the technology point of view, text extraction could be divided into two steps. First, your ML engineers will need to detect text appearances in the image. An ML algorithm can sort of scan the document and isolate the areas where there is any text in there. One way of doing this is to draw boxes around any text that the ML model identifies — a single word or a group of characters gets locked in a separate box.
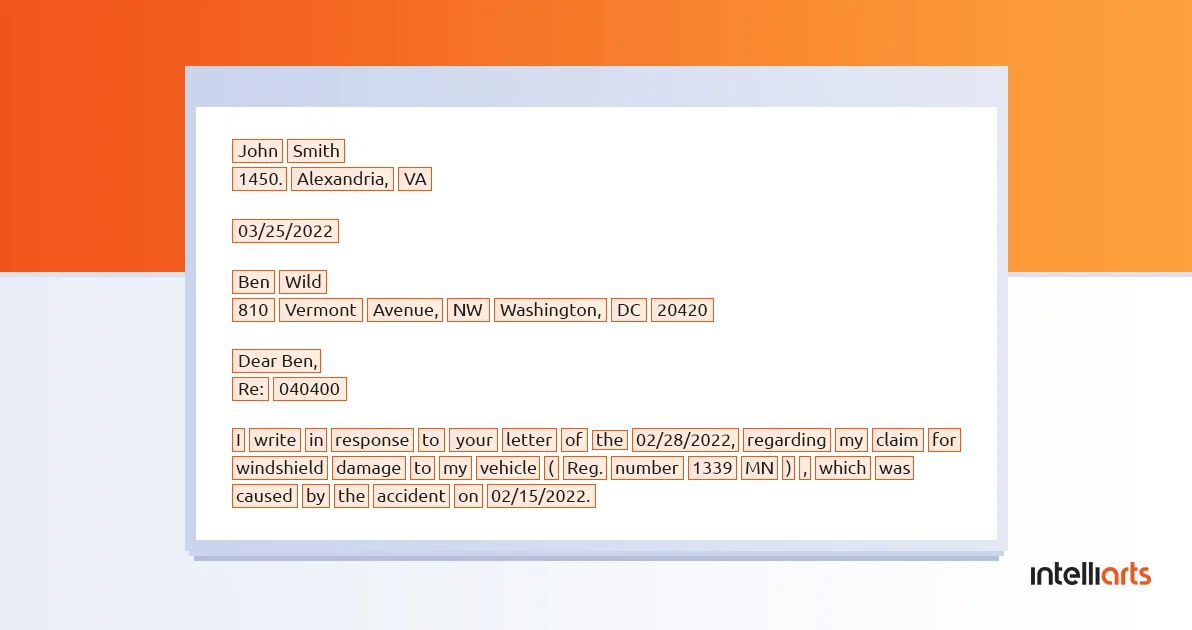
The next step for ML is to convert the text into a machine-understandable format. This means presenting the unstructured PDF text in the structured format so the agent could use it for their benefit. Generally, we can distinguish between three main approaches here:
1) Classic computer vision techniques: In this scenario, ML engineers have to use filters so the characters become visible against the background. Then, contour detection is applied so the characters could be recognized one by one. Image classification is the last step that will help with the identification of the characters.
2) Specialized deep learning approaches: As a special form of ML, deep learning is based on neural network architecture with many (deep) layers to be trained. This way, ML engineers don’t need to select any features before training the algorithm(s). With specialized deep learning approaches for information extraction, we can speak of algorithms like EAST (Efficient accurate scene text detector) or CRNN (Convolutional-recurrent neural network).

3) Standard deep learning: ML engineers can also choose a more standard deep learning detection approach, which means using algorithms like SSD (Single-Shot Detector), YOLO (You Only Look Once), and Mask R-CNN (Mask Region-Based Convolutional Neural Network).
Steps of data extraction development
Now let’s briefly outline the four major steps of how to develop an ML-powered data extraction solution:
- A good starting point will be to determine your business goals and specific objectives that you want to achieve with your data extraction solution. For instance, this could include the details like what documents you’d retrieve your information from or what information would it be (text only, graphics, etc.). All this will affect the approach and the tools you will use (we’ll talk about them in a few minutes).
- Next, you will work with data, which is the backbone of your ML solution. The company should have a good understanding of the data you have or need to strengthen the future solution. Research your data sources, explore their quality and quantity, and make an informed decision about data collection and the potential use of open datasets.
- During the data preparation process, data scientists transform raw data, so they could run it through ML algorithms to get important insights and make predictions. Data preparation includes data pipeline design, data processing, and transformation.
- Finally, data engineers can move to building an ML model and training a neural network. The size of the dataset doesn’t matter; large datasets work well as well as small ones. However, it’s important to have relevant data as the data quality directly impacts the efficiency of the ML model in the future. Also, monitoring the results of your solution is a must for the project to be successful.
Read also: Data Preparation in Machine Learning
At the end of the project, your company should get a workable tool that will allow you to extract text out of PDFs, preferably in some meaningful blocks that the system will then submit to the user on request. As a full-cycle ML project, data engineers could also develop a user-friendly interface so that employees with no technology background can also use the ML solution easily.
Implementing ML-based data extraction in your workflow
Building a machine learning solution is yet half the success. Your next step is to get the team on board to adopt this new data extraction tool. To do so:
- Under the guidance of data scientists who built the ML model, organize staff training to teach the personnel how to extract data with the help of a new tool. Aside from basic rules, the experts can provide some advice on how to use the solution the most productively as well as cover all the questions your team may have.
- Make your machine learning tool as explainable as possible. To build trust between the team and the machine, you’d better tell your personnel how machine learning works, the data you used to feed the model, and the benefits it could bring. As a result, the staff will be more motivated to incorporate ML-based data extraction into their workflow.
- Address security and privacy issues as usually the main concerns when it comes to emerging technologies. Prove that your company cares about these issues and has a clear policy on how to prevent data leakages.
ML-based data extraction tools
As said, today’s market counts multiple PDF data extraction tools for using machine learning to extract data from PDF. This OCR task is complicated, though the availability of ready-made solutions that data engineers can use in order not to build the model from scratch is obviously a big advantage. We review the three most popular document extraction tools that are commonly used to build an ML solution.
Amazon Textract
Amazon Textract is a deep learning-based service for automated data extraction from PDFs, though it works well for both handwriting and any type of scanned documents. Unlike lots of OCR software that relies on manual configuration, this tool can read and process a PDF document effortlessly and extract the information accurately and in no time.
With this tool, an employee just uploads, for example, a claims document, and gets back all the texts, tables, and forms in a more structured way. As with any ML tool, Amazon Textract is prone to continuous learning. With more data fed into the system built upon this tool, data extraction will become more productive for your company.
Tesseract OCR
Tesseract OCR is an open-source text recognition engine, which is also recognized as the most widespread and qualitative OCR library. Its latest version, Tesseract 4.00, is distinguished by configured line recognition wrapped in the new neural network system based on LSTM (Long short-term memory). Still, it also preserves the legacy of Tesseract 3, focusing on recognizing character patterns.

The primary advantage of this tool over other data extraction tools is the support of an extensive variety of languages, even Arabic or Hebrew. Another unique feature of Tesseract includes its compatibility with many programming languages and frameworks.
Cloud Vision API
Delivered as a Google Cloud service, Cloud Vision API is a powerful assistant for developers in integrating vision detection features, including OCR. The same as the two other tools discussed, Cloud Vision can detect and retrieve text from images, PDF files included.
The tool has two annotation features (data features): text detection and document text detection, though your data engineers will be interested in using the latter. Document text detection helps with data extraction specifically optimized for dense texts. In ML, density is associated with printed and written texts and is contrasted to the concept of sparsity when the text is written “in the wild”, for example, graffiti on the wall.
Get your PDF data extraction software with us
With deep expertise in AI, data engineering, and machine learning, Intelliarts specializes in building full-cycle data-driven and ML-powered software solutions. Our expertise includes machine learning, NLP, computer vision, predictive analytics, and more.
Data extraction is among our key strengths, enabling us to create efficient and accurate solutions tailored to various industries’ needs. Whether you’re dealing with extensive knowledge bases, vast amounts of unstructured data, or the need for precise and quick data retrieval, Intelliarts has the expertise and technology to deliver perfect PDF data extraction solutions.
Let’s review a couple of success stories that highlight our capabilities:
Data extraction chatbot
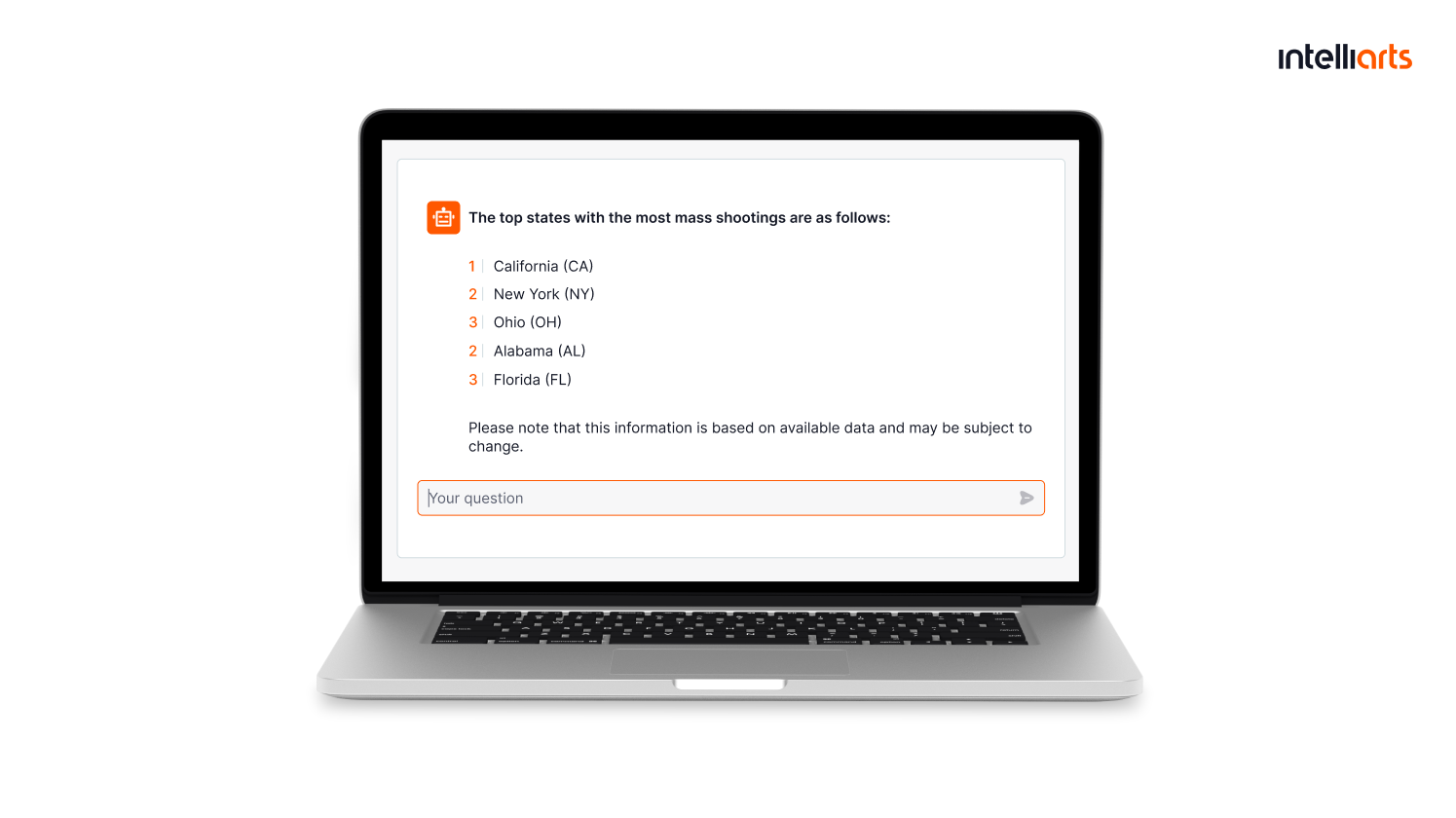
Business challenge: A non-governmental organization (under NDA) that advocates for gun control and against gun violence contacted Intelliarts to create a data extraction chatbot tailored to their needs. The NGO had an extensive knowledge base about gun safety and gun violence, which was growing dynamically so it was becoming more difficult to browse through this vast amount of data.
Solution: Our ML team developed a chatbot using the GPT-4 model, designed to facilitate rapid data extraction through free text requests and interpret the information as expected by the user. Trained on the NGO’s data, the chatbot worked exclusively with gun safety and related topics, providing references for users who wanted to verify information or delve deeper into a subject.
Business outcomes: The information retrieval system we developed proved to be a powerful tool, significantly enhancing our partner’s ability to find and interpret information efficiently. The system is fast and user-friendly, reducing the time needed for search and information analysis from hours to minutes.
Read the full success story on the data extraction chatbot.
Questionnaire assessment solution

Business challenge: An expert network firm specializing in legal assessments contacted Intelliarts to develop a data extraction solution for assessing the likelihood of individuals committing crimes based on mental health questionnaires.
Solution: Intelliarts created a specialized ChatGPT prompt tailored for extracting data from mental health questionnaires. The solution included an application that allowed users to upload questionnaires and set assessment rules, leveraging OpenAI’s GPT for quick and effective data analysis.
Business outcomes: The solution provided by Intelliarts enabled legal professionals and firms operating in security assessment fields to conduct rapid and accurate evaluations of potential crime probabilities. By automating the data extraction process, the solution reduced manual effort, improved assessment accuracy, and facilitated quicker decision-making processes.
Wrap up
ML-based data extraction could be very useful for businesses that collect volumes of data daily and via multiple channels. Many companies strive for automation and seek ways to harness their information, on the one side, and process the data quicker, on the other. With automatic data extraction from PDFs, businesses can retrieve info from PDFs seamlessly and fast, which can significantly improve daily repetitive tasks.
However, the development of this data extraction tool requires a certain expertise in machine learning and data science services as well as deep industry knowledge. In case your company cannot cover this expertise through their own efforts, Intelliarts has a great team of ML professionals and data engineering consultants, and we’ll be glad to help you.
Together we’ll make any manual data extraction and processing a thing of the past for your company.
Want to get started with machine learning in insurance? Or maybe optimize your existing ML system? Contact our talented ML engineering team, and we will gladly help you improve your business operations.

FAQ
1. How does automated data extraction from PDFs differ from manual data entry?
Automated PDF data processing and data extraction are much faster, more efficient, and more accurate than manual data entry. We avoid the human factor so precision will be better. Meanwhile, employees get time to focus on more challenging and interesting tasks.
2. What types of data can be extracted from PDF documents?
Usually, we’re speaking about text data, structured information such as tables and forms, metadata like document properties, images and graphics, hyperlinks, annotations, etc. Extraction methods vary based on the type of data and often involve tools such as PDF convertors, OCR software, and machine learning models for deeper analysis and processing.
3. How does automated data extraction impact customer service?
Customer service benefits from automated data extraction due to streamlined processes, reduced response time, and higher accuracy in handling customer queries and requests. This efficiency allows customer service teams to focus more on personalized interactions and problem-solving rather than manual data entry, ultimately leading to higher customer satisfaction and retention.









