

Object counting is an important and challenging task in computer vision, which has lots of real-world applications. From product counting for conveyors and production lines to traffic flow monitoring, object counting aims at estimating the number of elements from a still image or video. As a result, business stakeholders get a chance to respond to events properly in real time. In the case study below, we describe our recent project when we helped our partner get more accurate results in counting objects and significantly contribute to its counting application.

Business challenge
Our customer is a software development company that has been specializing in computer vision technologies since 2003. The company contacted us regarding its project on counting automation. Every day counting tasks are tiresome and monotonous, but unavoidable in many industries, such as manufacturing, pharmacy, or retail. In the production industry, employees count lots of similar objects, for example, pearls or buttons to get to know the exact number of things that were produced, transported, or arrived on a daily basis.
Being assured of our machine learning expertise, our customer asked us to research a reliable tech solution to ease the customer’s routine by:
-
Reducing the time spent on counting objects
-
Eliminating human error
-
Preventing double counting
At the discussion stage, the customer also provided us with examples of photos that its customers take for each counting template of its counting app. Overall, we received around 100 photos for each of the templates.
The solution for counting is delivered
Investigation stage
Right from the start, it was evident that our customer wanted to implement computer vision object detection using machine learning. This computer vision technology could help the app users identify and track down things in an image or video.
To translate the future solution into a wider business opportunity, we also proposed to the customer the idea of making this object detection solution mobile-friendly. From our side, the team was ready to go the long path and choose a light-weighted ML model with fast inference so it was deployable for mobiles.
When it comes to object detection using machine learning, there are at least two approaches to adopting this technology. We’ve decided to investigate the pros and cons of both and choose the most suitable solution for our customer.

A more traditional ML-based approach to counting problems wasn’t the best option in our case. For one thing, this solution required the manual selection of counting templates, increasing the time spent on choosing templates. For another, the accuracy suffered as the solution grouped objects based on self-similarities, such as geometry. Thus, if you planned to count coins, the technology risked counting all round objects in the image.
A more recent and state-of-the-art deep learning approach was more promising, and it was what we offered our customer at the end of the day. This solution employed neural networks that allowed the system to decide what counting templates to use automatically. On top of this, building an object detection algorithm based on deep learning could help our customer to increase the accuracy of counting.
Read also: AI for Car Damage Detection.
Implementation stage
1. Classification training
Being our customer’s technology partner, we took total ownership over the development part and started with image classification. Its idea lies in using ML algorithms and computer vision for object detection to interpret the content of the image. In simple words, the system analyzes the input image and comes back with a label to categorize the image.
In our case, we decided to use a pre-trained MobileNet_v2 network (below) with high precision, lightweight, and fast. A pre-trained network was a reasonable choice for us since we didn’t need to develop it from scratch, gather additional data, or use computer resources for model training. The model was initially trained to extract valuable features from images – we just needed to accommodate it to our needs.
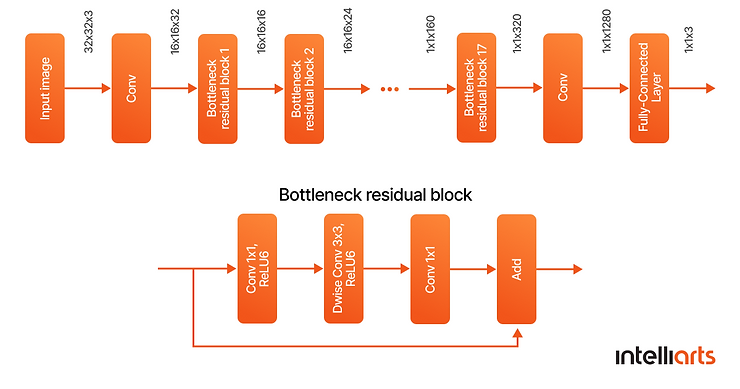
Moving along the ML pipeline of our project, we started training an algorithm with around 100 images and ten most used counting templates that the customer provided to us. As a result, we fine-tuned our network for a few iterations and achieved good results, with an accuracy of 91% in test images.
Below we give a confusion matrix to help you visualize the performance of the algorithm. In the matrix, rows are actual classes, and columns are predicted classes. Numbers stand for the number of samples predicted with class i and actual class j, where “i” is the row number (predicted class) and “j” is the column number (actual class). Hence, in the best possible scenario, values i not equal j are zeros, and numbers are only on the main diagonal.

Although our primary results were satisfactory, this matrix shows us that there were a few mistakes for classes 1, 2, 3, and 6 that we incorrectly predicted as class 7 or 9. We solved this problem by collecting more data and using them to optimize our computer vision pipeline. This way, we trained our model to understand the difference between these classes and minimize mistakes in the confusion matrix.
Additionally, we brainstormed a way to improve accuracy: we planned to make the system return three high-probability templates instead of one and ask the user to select it. A brief “aha” moment and the achieved accuracy was 100%.
2. Object detection training
The next part of our project involved machine learning to detect and count objects in the image. Unlike in object classification, where we trained the system to match an object in the image with a class, our new task was to detect whether the class existed in the image or not.
Here we consulted the сlient and decided to test the solution only for one template (coins). We planned to check how difficult it was to train the algorithm and how accurate the results would be before testing it for other templates.
When we moved to selecting computer vision object detection models, we agreed on comparing a pre-trained FasterRCNN network vs. YOLOv5. While these two are the most commonly used in the industry, they also show high speed and robustness. Although YOLOv5 is an even more popular approach, it’s not one-fits-all, and we decided to pilot our way and choose the better fit experimentally.
Training YOLOv5 on around 2000 images of coins and fine-tuning FasterRCNN on 200 images proved that the first one was a poor fit for our project. The model failed to produce accurate results working with small objects that are close to each other. Eventually, we opted for pre-trained FasterRCNN.

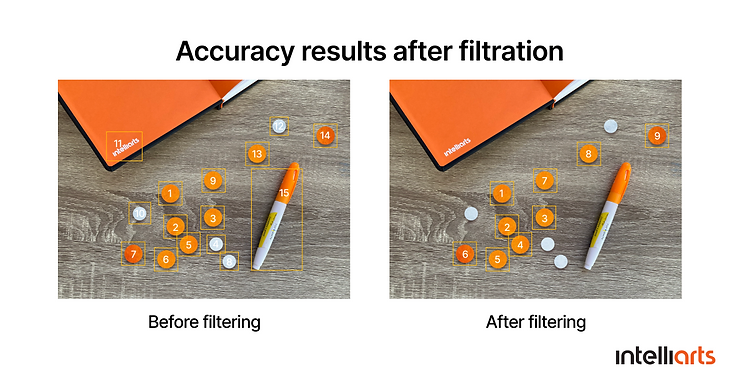
To improve the results, we also added a few business logic filters after the prediction of the neural network was achieved. Here are the filters we used:
-
Confidence – for objects with more than 80% confidence
-
Size – to drop objects that are way too big or small than others
-
Overlapping – to drop objects overlapping for more than 30%
Business outcomes
As a specialized form of machine learning and AI, deep learning is a relatively new technology, but it added greatly to the momentum of object detection. From detecting defects to automatically counting objects, object detection using machine learning can come in handy to your company in the way it was useful to our customer.
So far, our project resulted in:
-
A breakthrough solution for our customer. At the end of the day, our solution combined two neural networks. If the image gets to the classification network, and the object appears in the top three most likely templates (1), then the image goes to the object detection network and returns the right image with boxes drawn around each detected object (2).
-
High accuracy. By applying ML industry best practices along with considering insights that we’ve got throughout our experience, we helped our customer to improve its service as well as significantly add to the accuracy of its counting application.
-
Mobile-friendly app. To provide additional value to our customer, we’ve wrapped our solution to API with Flask. This way, a user just sends a photo, and when it’s returned, they have a counting template, the image with the detected objects, and the number of objects.
As ML experts, we always aim to establish fruitful, long-term cooperation with our partners, and this project helped us win one more loyal customer that we hope to continue our collaboration with.
If you’re interested in implementing an ML-based project successfully, don’t hesitate to contact us. ML experts from the Intelliarts team are ready to help you.

FAQ
1. What are the key components and algorithms used in object detection systems?
In object detection, we usually speak about the next ML algorithms: Fast Region-Based Convolutional Network (R-CNN), Faster R-CNN, Spatial Pyramid Pooling (SPP-net), Histogram of Oriented Gradients (HOG), Single Shot Detector (SSD), You Only Look Once (YOLO).
2. What challenges and limitations should businesses consider when implementing object detection systems?
When implementing object detection, businesses should remember about limited annotated data availability, the need for additional training when new data appears, and multi-model detection, i.e., the use of new sensing modalities such as thermal cameras in manufacturing.
3. How can businesses get started with implementing object detection solutions of Intelliarts?
Write to us to schedule a short meeting where we’ll talk about your business challenge and/or object detection idea. As a technology consulting company, we can provide you with all the technical requirements for your project and give relevant advice, as well as help you implement the project.








