

Solution Highlights
- Created an AI chatbot for data extraction from the internal knowledge database in a fast and easy way
- Trained the LLM to carry on a conversation about gun safety and related topics
- Reduced the time needed for search and information analysis from hours to minutes
- Helped the customer save hours on operational tasks and maximize efficiency

About the Project
Customer:
A non-governmental organization (under NDA) that advocates for gun control and against gun violence contacted Intelliarts to create an AI-powered data extraction chatbot tailored to their specific needs.
Challenges & Project Goals:
The NGO has an extensive knowledge base about gun safety and gun violence. As this base is growing dynamically, it’s becoming more challenging for the customer to browse through tons of data and search for the necessary information. The company wanted to solve this challenge with the help of an AI assistant — a chatbot that should allow the customer to extract data from their internal knowledge database in a fast and easy way.
For a comprehensive comparison of AI models like Claude and ChatGPT, which can be utilized in similar data extraction tools, refer to our article on Claude vs. ChatGPT.
Solution:
At the end of this project, the Intelliarts ML team built a chatbot using the GPT-4 model, which extracts data quickly through free text requests and interprets it in a manner expected by the user. The chatbot is trained on the NGO’s data and can carry on a conversation exclusively about gun safety and related topics. It also provides references as additional information in case a user wants to verify whether the tool works properly and go deeper into the topic.
As part of the process, extracting training data from ChatGPT played a key role in tailoring the chatbot to meet the specific informational needs of the organization.
Business Value Delivered:
The information retrieval system that we developed proved itself a powerful tool that helps our partner find and interpret the information in the most efficient manner. The system is fast and user-friendly and has reduced the time needed for search and information analysis from hours to minutes. As a result, the chatbot helps the customer save hours on operational tasks and maximize efficiency at the workplace.
ML Development, Data Analysis, Cloud Services, Data Science
Technology Solution
To help our partner find and extract data easily, our ML engineers built a robust information retrieval system wrapped in a chatbot. We can distinguish four important milestones in the development process:
Discovery stage
The customer’s dataset was composed of two types of data: textual and tabular. Our ML team started with processing the textual data, which included news, press releases, articles, etc. that we extracted from the company’s websites devoted to gun safety.
In the first iteration, our ML engineers parsed the data in order to convert it into the necessary format and loaded it into the vector database. In machine learning, models work with numbers rather than textual data. And since a vector database stands for a collection of data stored as mathematical representations, we needed it to be able to interact with the data further.
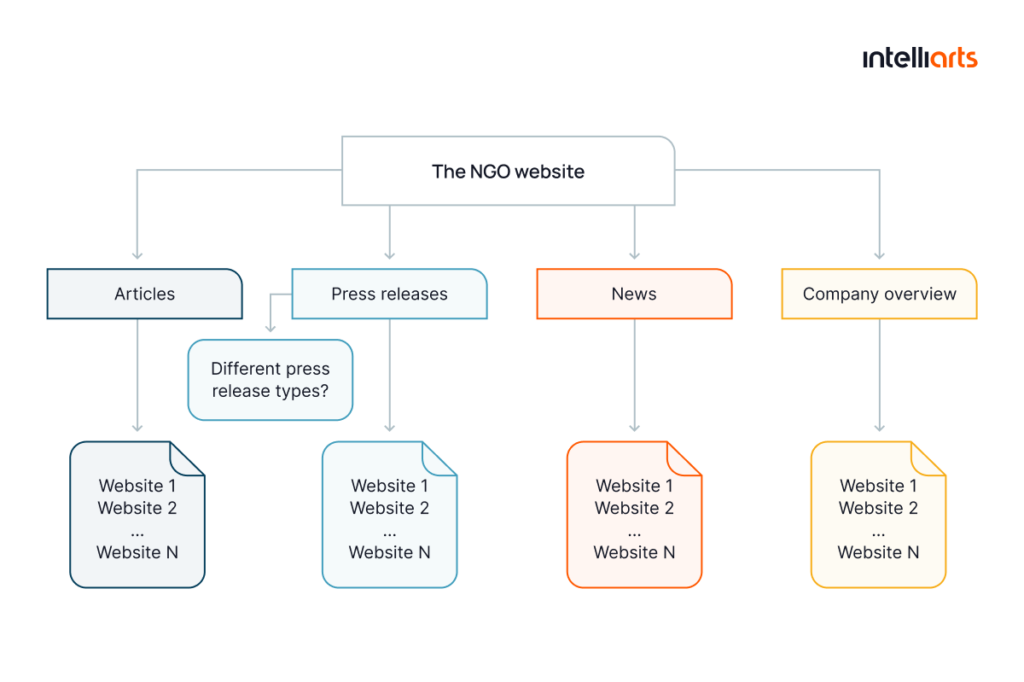
Example of how we categorized one of the sources for text data
The next step was the actual development of the ChatGPT-powered chatbot. For this, our specialists chose a retrieval augmented generation (RAG) approach, the idea of which is to increase the accuracy and reliability of large language models (LLMs) at the expense of facts extracted from external sources. Specifically, whenever we had a user request, the system went to the vector database to find relevant information and submit it to the LLM. Based on the request, the found information, and the early written prompts, the model generated a response.
This method enabled ChatGPT for data mining, ensuring that the responses were informed by reliable, relevant data extracted from external sources, enhancing the model’s performance and accuracy.
Overall, all this was a baseline in the project to build the PoC and see whether the solution overlaps with our expectations.
Processing tabular data
We then moved to processing the tabular data, primarily statistics about gun violence. It’s important to mention that LLMs usually have difficulty understanding unstructured tabular data. So, our ML engineers started with feature engineering to improve the performance of the ML algorithms. For each table, we cleaned up the data removing duplicates, correcting errors, and filling up the gaps.
One of the biggest problems here was the lack of data consistency as the same information could be stored at different places. So, the issue of understanding data, as well as properly structuring and organizing it, arose as the LLM didn’t know how to access data correctly.
We solved this issue by merging several tables into one. Our specialists also asked for the raw data instead of the aggregated one so the model could make the calculations by itself for better accuracy. Finally, we used multi-indexing to categorize the data, for example, based on the topic (e.g. gun safety laws) or the type of content (e.g. press releases).
Next, our ML team introduced the agent table processor, another LLM that helped us analyze the tabular data. In general, understanding tabular data is another big challenge in AI/ML, and there are a few approaches to this task. After some research, our ML engineers chose an LLM agent as the most appropriate in this case:
- For the agent to be able to analyze the data, it transformed the user’s query into the Python code, ran it in the secure environment, and sent it back to the LLM.
- Based on the result, the LLM generated a human-like adequate answer for the user’s request.
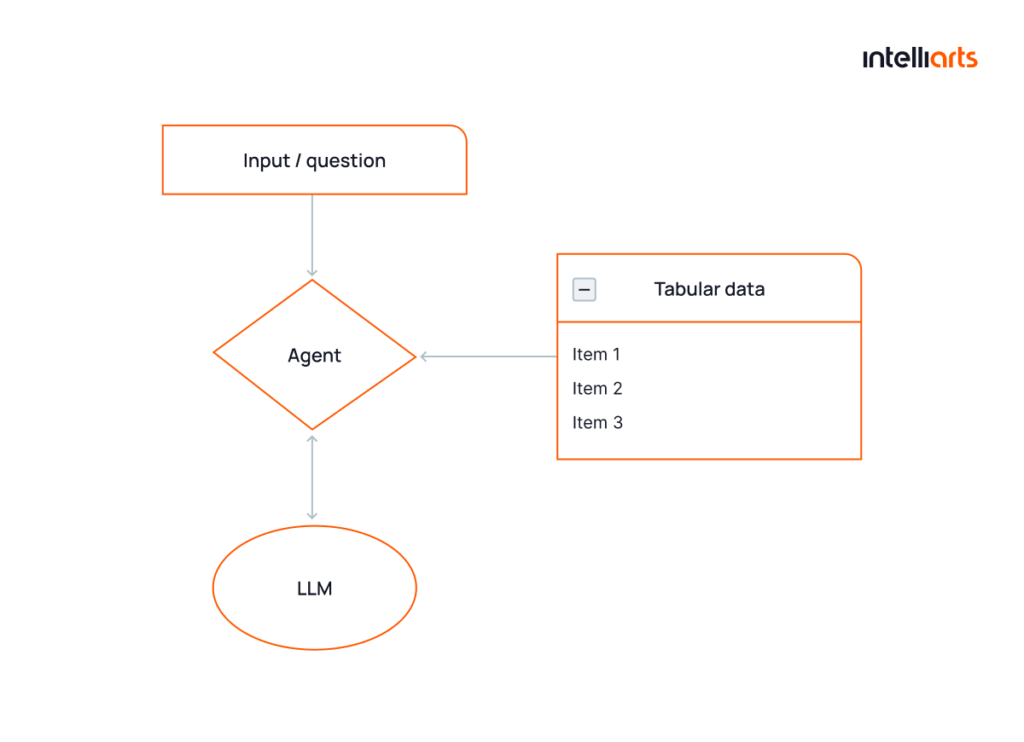
Introducing an agent table processor
Implementing an embedding router
Our next logical step was to combine the knowledge base composed of the articles and press releases with a set of agents that work with tables. To do it properly, we added an extra layer of an embedding router, which complicated the whole process but should help us determine the nature of the request and act accordingly.
Since most of the users’ requests related to the tabular data have a similar structure, we can differentiate them from those related to the knowledge base. So, whenever a new user query appears, the embedding router initiates a decision-making process: either it categorizes the request as a report and directs it to the knowledge base or as a table and directs it to tables.
Extra “general” type of requests
In v2, we added one more type of request categorized as general. This type had to cover general inquiries or tasks not specifically related to the knowledge base. For example, these could be cases when a user needed to simplify answers or asked completely off-topic questions. By crafting effective prompts, we adjusted the behavior of our chatbot:
- Since our ML engineers were developing a personalized chatbot, we trained it to answer only the questions related to gun safety and gun violence.
- We also safeguarded our solution from the prompt injection that aims at data leakage.
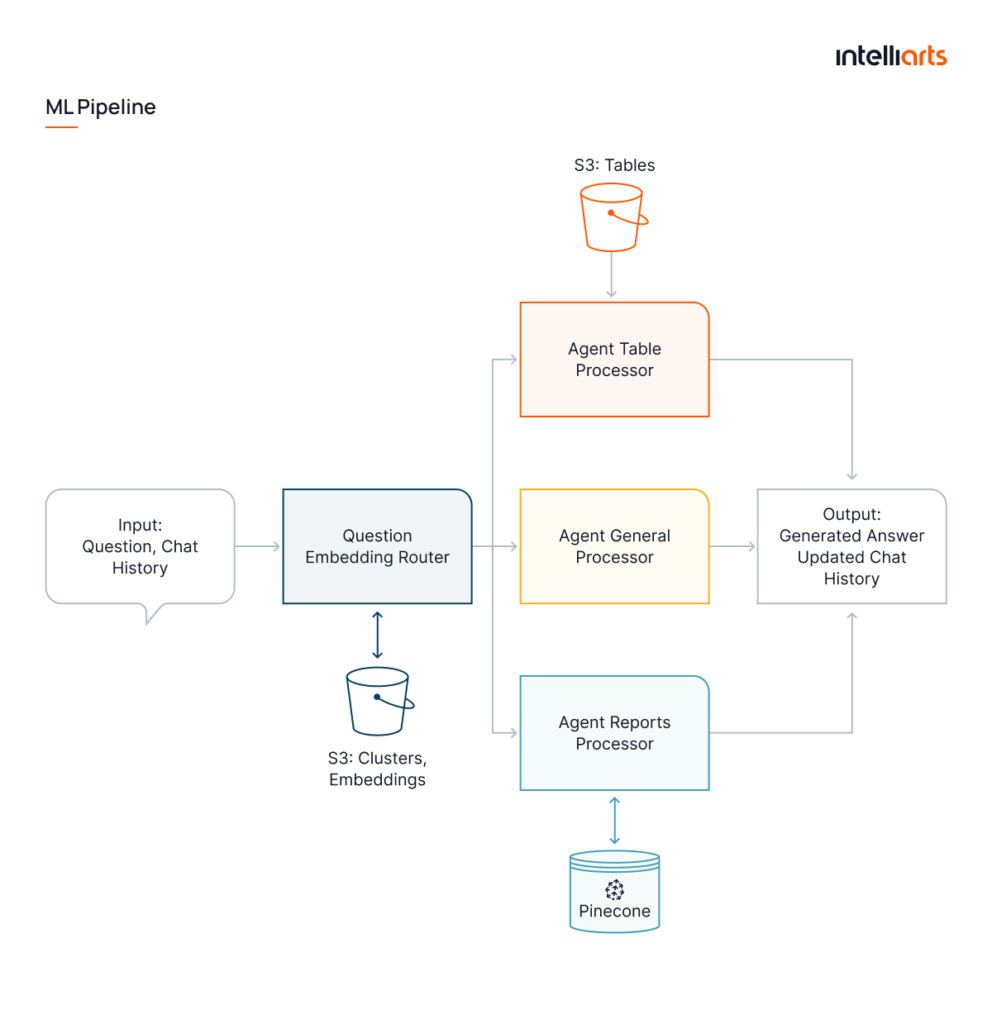
ML pipeline for the Data Extraction Chatbot
All in all, the Intelliarts team created a ChatGPT-enabled solution for AI document extraction. This AI assistant receives the user input, either a question or request. Additionally, the solution integrates chatbot-powered data extraction, allowing the chatbot to efficiently retrieve and process information, streamlining the extraction process for more accurate and relevant results. Based on the input, the system employs embedding routing to understand the nature of the request and categorize it as:
- Report: For the first type, the system will be looking for answers in the knowledge base, using an RAG approach.
- Table: If the request intends calculations or data retrieval from tables, we route it there. A specific prompt-driven system then decides what tables are relevant and selects an agent to handle the request.
- General: For history-based questions or tasks, we use a general-purpose agent. This agent can restrict the scope of questions or handle requests like summarizing sources, etc.
Besides, the chatbot understands the context of a conversation and saves up a chat history. The user can switch between different types of requests like first asking about tables and then returning to articles. We also trained the model so it mimicked our partner’s tone of voice. The chatbot should sound polite and professional. But like the NGO, it also emphasizes on victims instead of guns or criminals in its communication.
Business Outcomes
AI chatbots are gaining popularity in business today since they allow employees to delegate repetitive tasks and free up time for more creative jobs. Custom AI assistants are an even better solution as they’re tailored to the specific needs of the company. Respectively, our partner pointed out a list of gains received from using the newly developed AI chatbot data extraction system, which made retrieving data more efficient and aligned with their specific requirements:
- Automation: Our chatbot works really fast and, therefore, automates routine tasks effectively. If earlier an employee had to look through tons of articles to find the necessary information, now the data is at their fingertips. The employee can access the right article in a few minutes and even summarize its key points if needed.
- Better productivity: With less time spent on access and analysis of information, the company can expect increased productivity. As mentioned by the customer, the chatbot saves hours of work, and the employees have time to focus on other tasks.
- Streamlined decision-making: Indirectly, the AI assistant helps to make decisions faster and more data-driven. Employees can go through much more material in less time. So, they’re more informed about the topic and theoretically can make better decisions.
- Personalization: The chatbot we built was developed specifically for our partner. So, it suits perfectly for the tasks performed in this industry and company. It also mimics the NGO’s tone of voice and overall adheres to its policy.
- Ease of use: No special training is required to use the solution. It has a user-friendly and intuitive chat interface, which we’re all familiar with thanks to social media and messengers.
- Integration with existing systems: The chatbot isn’t a standalone tool. It’s integrated with the partner’s existing system, which enhances the company’s workflow rather than disrupting it.




