Discover applications of OpenAI for data extraction tasks. Review related use cases and explore the limitations of the technology.
Since the release of ChatGPT by OpenAI in 2022, most people in nearly all industries have tried a generative AI tool at least once. The market size for Generative AI is expected to show a CAGR of 24.40%, resulting in a market volume of US $207 billion by 2030. The technology can come of usefulness in multiple ways. One such is extracting data from documents with OpenAI.
Read this post to discover applications and use cases of ChatGPT-based AI to extract data from documents, the challenges and limitations of the technology, and its prospects.
How can OpenAI GPT help extract data from documents?
ChatGPT by OpenAI is a Large Language Model (LLM) designed to understand and generate human-like text based on the inputs it gets. The technology leverages large-scale ML and Natural Language Processing (NLP), enabling applications such as generative AI in marketing, and allowing it to provide an answer to a data extraction question based on a specific query.
If you’re exploring how to automatize reading documents with GPT, you can apply this technology across a variety of document extraction tasks, such as summarizing, processing, and interpreting key data points automatically. In enterprise RAG (Retrieval-Augmented Generation) systems, integrating ChatGPT can enhance the accuracy and efficiency of document data extraction processes.
Among the top large language models, ChatGPT stands out for its advanced capabilities in document data extraction. Let’s get started with reviewing applications of OpenAI GPT in this field. This list of possible ways to use the technology includes but is not limited to:
Contextual understanding. Grasping the context in which words or phrases are used. This capability is crucial for tasks like sentiment analysis, machine translation, and dialogue systems.
Automated responses. Extracting and interpreting customer queries from emails or text-based support channels to provide automated but accurate responses. It’s also useful in knowledge management, where automated FAQs can be generated or updated.
Text summarization. Generating concise summaries of long documents, reports, or articles which aids in quick decision-making and information dissemination.
Named Entity Recognition (NER). Identifying and classifying named entities like names of persons, organizations, locations, expressions of time, quantities, and more. This is important for information retrieval, data mining, and customer service bots.
Question answering. Receiving a question and then providing an accurate and concise answer. This can be applied in domains like customer service or academic research.
Invoice processing. Extracting relevant financial data from invoices for automated entry into accounting systems.
Medical records management. Extracting and summarizing critical information from health records for easier access and interpretation by healthcare professionals.
Market research. Analyzing news articles, reports, and other documents and extracting data points like market trends, customer preferences, or competitive intelligence.
Resume screening. Sifting through resumes to extract educational background, skills, experience, and other relevant information for automated initial screening.
Automating AI chatbot data extraction, especially with OpenAI GPT, can be helpful in many ways, depending on the particular needs of businesses across various sectors.
If you wonder how to extract data from documents using ChatGPT from a technical perspective and require professional assistance, don’t hesitate to contact ML engineers from Intelliarts.
Examples of successful use of OpenAI GPT in a data extraction task
Despite generative AI technology becoming openly available not so long ago, it’s already being utilized extensively. Here are some of the real-world open AI-based document data extraction examples along with other generative AI use examples that showcase the growing popularity of the technology in the business landscape:
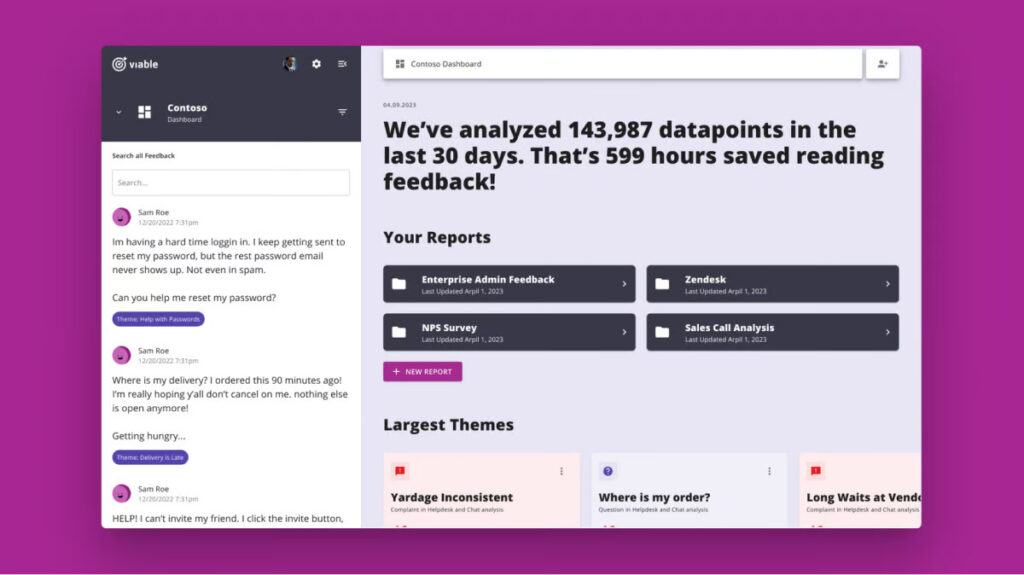
Viable generative analysis platform
The Viable platform allows companies to handle customer support tickets better and retrieve actionable insights from customer interactions to improve their Net Promoter Score (NPS).
They started exploiting the capabilities of fine-tuned OpenAI’s LLMs to analyze qualitative data on a scale that exceeds conventional techniques. This way they are able to help their customers to make sense of the vast amounts of data they generate through communicating to customers. The Viable’s customers claim that the generative analysis feature saves them nearly 1,000 hours per year.
Yabble feedback analysis platform
The Yabble platformallows companies to extract data from customer feedback to inform their business strategies and save time on processing data manually.
The Yabble Count, an AI tool powered by OpenAI ChatGPT, can analyze thousands of comments and other unstructured data sets, categorize them by sentiment, and organize data into themes and subthemes. Ben Roe, Head of Product at Yabble, says: “Users were loving how easy it was to finally understand mountains of data and feedback forms and have that information presented in a digestible way.”
It’s worth noting that generative AI is not the only technology capable of performing data extraction tasks. You may also utilize document extraction, non-generative AI designed to pull out specific information from documents, or rule-based document extraction software.
The detailed use cases are only a few of the numerous examples of adopted data extract with ChatGPT since companies tend not to disclose information about such matters. The scope of industries, businesses operating within which utilize ChatGPT data extraction broadly is shown in the infographic below.
First, let’s get to know the simple process of information extraction using ChatGPT, although similar Generative AI models can also be utilized for this purpose:
#1 Upload an image to ChatGPT
Convert your PDF files to images using any available converter software for this purpose. Then, simply drag the image into the ChatGPT window, or alternatively, upload it using the provided interface. This process may take a brief moment to complete. Verify that you’ve upgraded to GPT-4 if an image button is not visible.
#2 Enter a ChatGPT prompt
Enter a prompt that will detail the model of your task. When providing a prompt to ChatGPT-4, it’s important to adhere to the best practices for interacting with Large Language Models (LLMs). This will help ensure that the model understands your request and provides an accurate and helpful response.
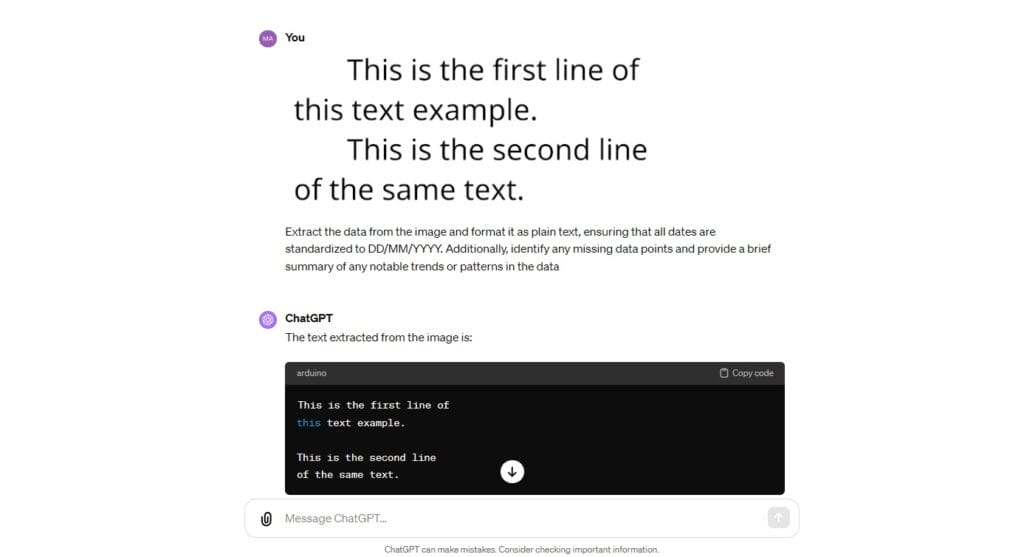
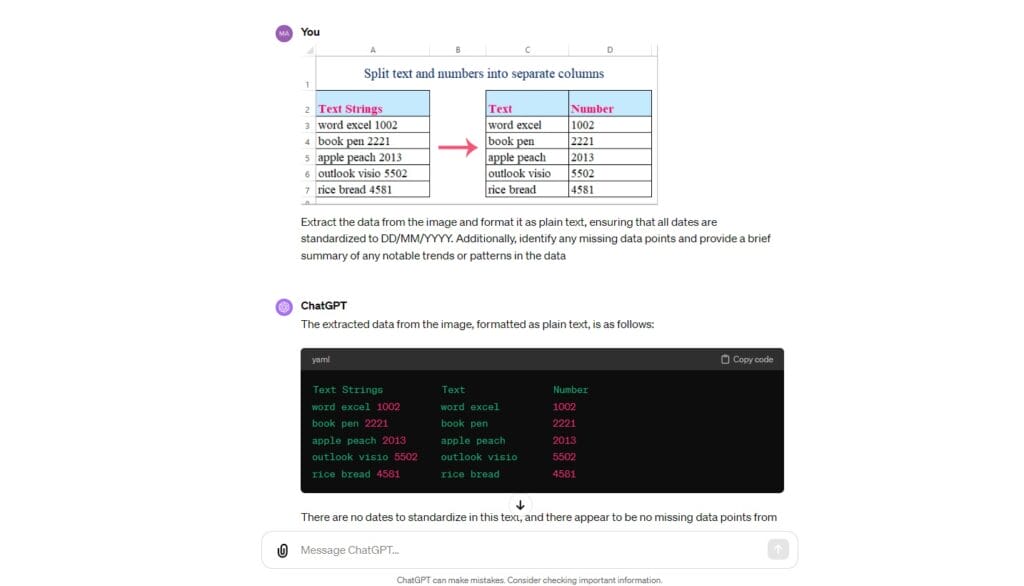
Prompt example: Extract the data from this image as plain text.
You may modify a prompt for complex extraction tasks or when there is a need for certain standardization:
Advanced prompt example: Extract the data from the image and format it as plain text, ensuring that all dates are standardized to DD/MM/YYYY. Additionally, identify any missing data points and provide a brief summary of any notable trends or patterns in the data.
Upon extraction, ChatGPT will provide text in the development environment as code.
#3 Verify the correctness of extracted data
Inspect the data before passing it any further and utilizing it. It’s crucial to quality-check the information extracted by LLMs, especially those designed for public use, as they may contain slight errors with significant consequences.
Here are several ways for data verification you may consider exploring:
Spreadsheet software: Use programs like Microsoft Excel or Google Sheets to paste the extracted data and visually inspect it. These tools can also be used to perform basic data checks and to compare extracted data against source data if available.
Text comparison tools: Tools like diff in Unix-based systems, WinMerge for Windows, or online services like Diffchecker allow you to compare the extracted text against the original document side by side to spot differences.
Regular expressions: Regex can be utilized to search for patterns that would indicate common OCR mistakes or to validate formats (like dates and numbers).
Machine learning quality checks: For more advanced needs, machine learning models can be trained to detect anomalies or outliers in OCR output data, flagging potential errors.
ChatGPT’s responses can be unpredictable, with varying levels of reasoning and accuracy. The system’s responses are dependent on the specific prompt and context of the user’s interaction, which means that identical prompts may yield different answers. Currently, there is no standardized approach to ensure consistent quality in its responses.
LLM-based automated data extraction with the opportunity to retrieve data through queries: RAG approach
Let’s get to know how to establish a system that is capable of extracting data from PDF and other files containing textual layers automatically and how to establish document nodes, i.e., non-relational (or NoSQL) databases, for the extracted data with the opportunity to retrieve information from it by using queries.
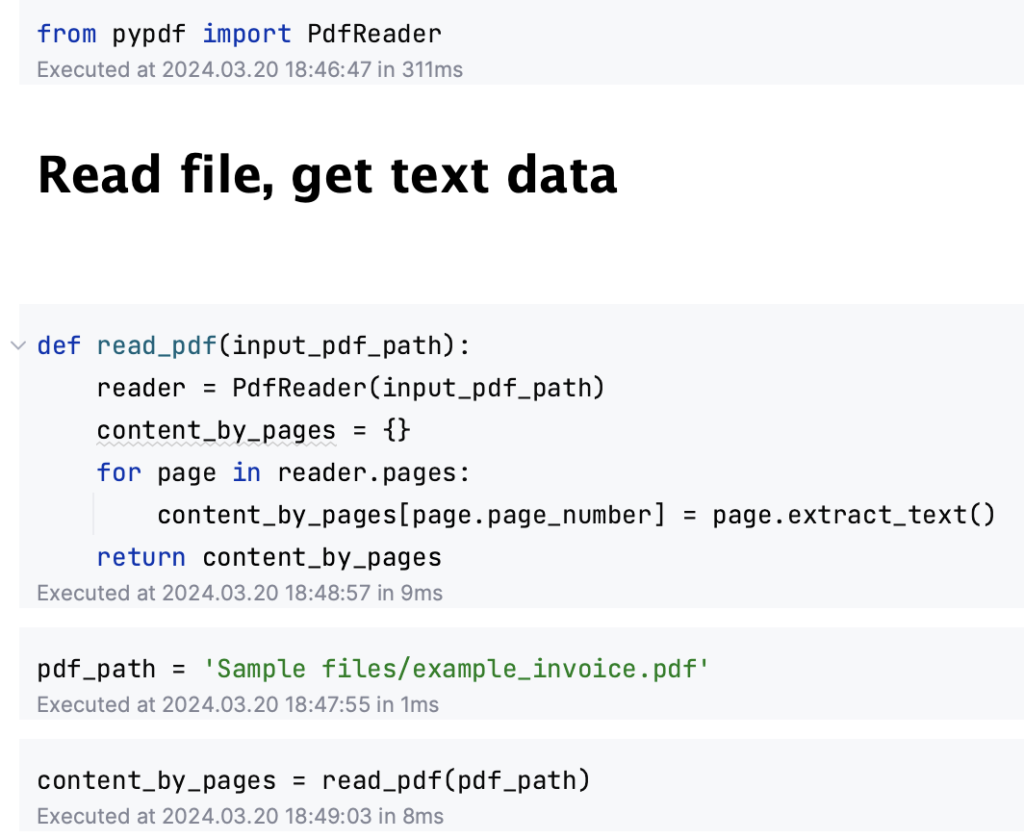
#1 Reading the file
First, you need to read the file from which you intend to extract information. If you’re dealing with PDF files, the PyPDF library comes in handy. This tool allows you to extract text from PDFs that contain text layers.
In the absence of text layers, Optical Character Recognition (OCR) libraries or layout Transformer models are recommended. These alternatives help in recognizing and converting images of text into actual text data.
An example of what the result of reading the file and extracting the text data is shown below:
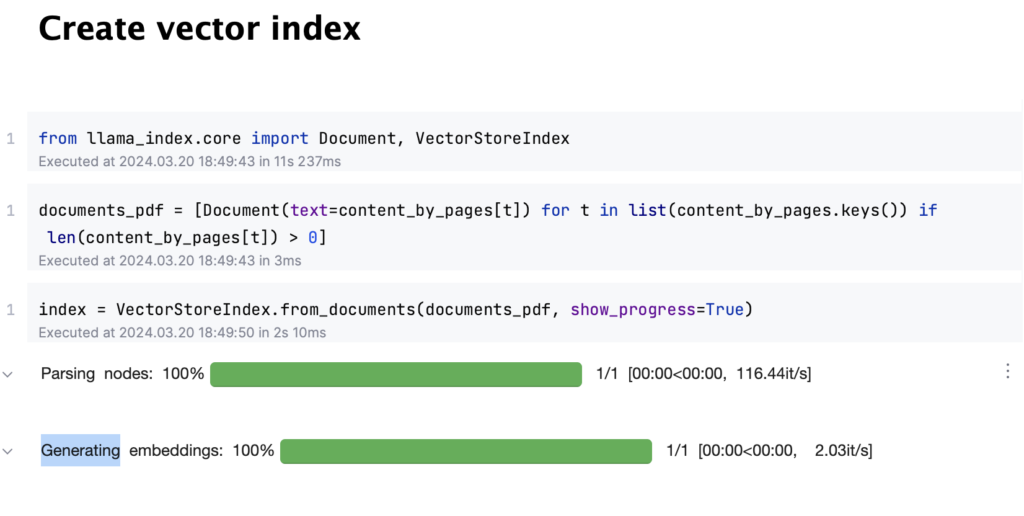
#2 Vector index creation and splitting text into chunks
After obtaining the raw text from your file, the next step involves creating document nodes using the llama-index framework. This process is crucial for embedding the text using models like OpenAI’s embedding model.
Large files may require splitting into text chunks, which can be done using various chunking strategies or sizes to manage the data more efficiently. Besides OpenAI, other embedding models like Cohere are also viable options. There are leaderboards available to review and choose from open-source models based on performance and suitability.
An example of creating document nodes is shown in the image below:
#3 QueryEngine interface
In this stage, you need to utilize the QueryEngine interface, which facilitates Retrieval Augmented Generation. The process includes two phases:
Phase 1: Retrieving chunks relevant to an input query or task. Phase 2: Utilizing an LLM to generate answers based on these relevant chunks.
This approach allows for more precise and relevant data extraction with ChatGPT and response generation.
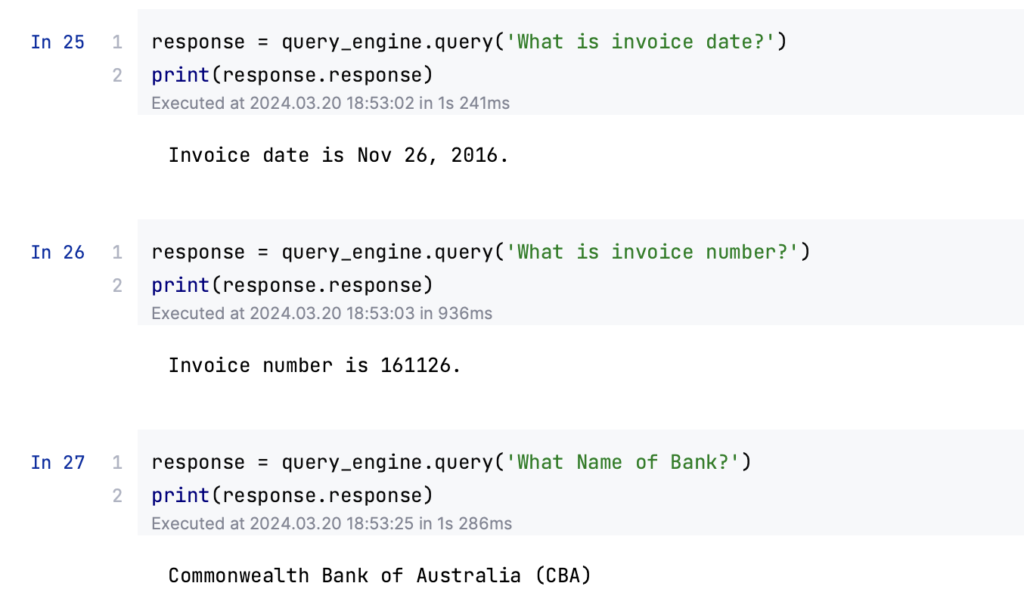
#4 Experimenting and results
At this stage, you can begin experimenting with the setup and recording the results. Adjustments and optimizations can be made based on the performance and accuracy of the data extraction and response generation. Example of what data retrieval based on query looks like is shown in the image below:
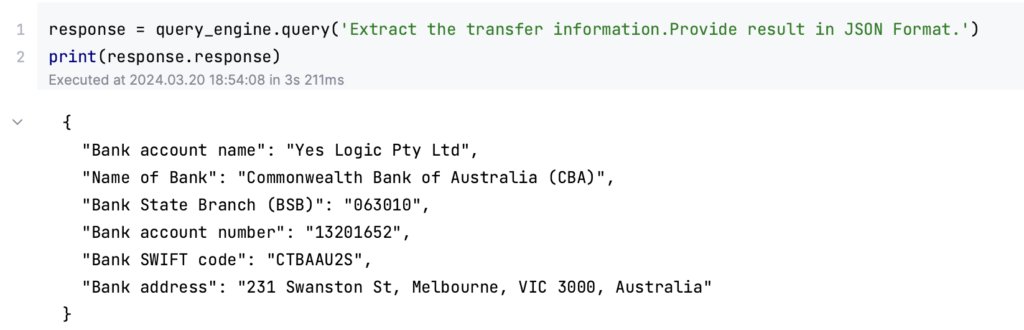
The system is also capable of providing structured outputs, like JSON, which can be particularly useful for integrating the extracted data into other applications or workflows seamlessly.
Challenges & limitations of GPT AI-based data extraction
As with any other technology, using AI to extract data from documents is not deprived of complexities you should be aware of. Here is a list of the major challenges of document data extraction via ChatGPT:
Ambiguity and contextual errors. While GPT is good at general language tasks, it can misinterpret ambiguous terms, resulting in GPT not always discerning the correct meaning based on context.
Difficulty with numerical data and visual elements. GPT models are primarily text-based. So, trying to extract statistical or mathematical data as well as analyzing complex document structures like tables, spreadsheets, or forms may not be error-free. It’s also true in the cases of dealing with PDFs that include images, diagrams, or graphs. For those, you’ll need additional tools that support OCR (Optical Character Recognition) and image recognition.
Legal and ethical concerns. If you’re extracting sensitive or personal information, GPT doesn’t provide any built-in privacy safeguards. This poses risks in terms of data security, and you may face non-compliance with regulations like HIPAA or GDPR.
Lack of accuracy & consistency. GPT can be inconsistent in its responses, even to the same questions about the same documents. So, it requires validation steps to ensure data reliability.
Lack of domain-specific knowledge. This mostly concerns general-purpose GPT LLM since specialized models are typically well-trained on domain-specific data. So, it’s worth understanding that the general model may not understand jargon or complex terminology.
Token limitation. Each GPT model has a maximum token limit, typically ranging from a few hundred to a couple of thousand tokens. This constrains the amount of text you can process in a single go, complicating the extraction from longer documents.
Document text extraction with ChatGPT can be recommended to utilize. However, it’s worth considering that the technology wasn’t specifically designed for this task. So, such solutions need customization and probably the use of additional instruments to become high-performance.
There are ways in which the listed challenges can be addressed through custom AI development. For example, a provider of such services can utilize a multi-modal approach, combining the benefits of different AI algorithms. Another opportunity is to add validation layers that check the accuracy and quality of ChatGPT model responses.
Partnering with the right ML service provider will ensure that technology limitations won’t be an issue during a project. Drop specialists from Intelliarts a line and let’s discuss the opportunities.
Future & prospects of document data extraction via OpenAI GPT
It’s possible to predict a growing utilization of data extraction using AI ChatGPT technology. The reason is that potentially, it can develop in the following ways:
Improved structure recognition. Future iterations could be fine-tuned to better understand structured data like tables, forms, or even coded languages, thereby making GPT models more versatile in document extraction tasks.
Ethical and legal safeguards. As AI ethics and regulations mature, built-in features for data privacy and compliance checks could become standard, mitigating legal and ethical concerns.
Integrated multi-modal capabilities. Next-generation versions could potentially integrate with OCR and image recognition technologies to handle documents with mixed media, making them more comprehensive in their extraction capabilities.
Error correction and validation. Advanced validation algorithms could be built in, either as part of GPT or as a complementary system, to automatically verify the accuracy of the extracted data.
Real-time updating and learning. If future versions can be updated in real-time or even adapted on the fly, they could offer more current and context-sensitive data extraction, addressing the knowledge cutoff issue.
Improved scalability. Advances in hardware and optimization algorithms could potentially address the token limitations, allowing for efficient processing of longer documents in one go.
Collaborative AI systems. GPT models could work in tandem with other specialized AI systems for even more effective and nuanced data extraction tasks.
When it comes to data extraction using AI, despite the technology’s limitations as of 2023, it can be significantly improved over the next decade. So, adopting generative AI today is the first step to utilizing the advanced technology to its fullest extent in the near future.
Here at Intelliarts, we have substantial experience delivering projects involved with NLP, generative AI, and associated technologies. Our related cases include the following:
Questionnaire assessment solution for an expert network firm
A challenge was to create a solution that would help in assessing how likely people are to commit a crime. The documents for data extraction in this case were the questionnaires filled out by the examinees. The initial purpose of the questionnaires is to complete a security designation form intended to assess mental health stability.
The solution was a specialized ChatGPT prompt, created and extensively tested by the Intelliarts team. We also developed an application that can help users utilize a prompt effectively by simply uploading filled-out questionnaires and assessment rules for them. With the help of this document data extraction via OpenAI GPT solution, businesses operating in legal fields or lawyers can run a quick and effective assessment of the probability of a particular person committing a crime.
A challenge was to ensure high-quality job description parsing and matching candidate profiles with job requirements. This would help the client to streamline candidate sourcing on the platform. As an additional requirement, the solution should comply with Diversity, Equity, and Inclusion (DEI) principles.
The solution was an NLP technology-driven ML model created by the Intelliarts team. It can compare candidate profiles from job boards or social media sites like LinkedIn with the positions that companies intend to fill. It’s done by analyzing textual descriptions and extracting and matching key phrases. The solution includes a semantic search engine that supports multiple search filters, such as age, gender, racial origin, etc., and shows over 90% accuracy for gender and ethnicity detection.
Looking for a trusted software development partner?
Intelliarts experts are here to discuss your needs.
Using ChatGPT AI to extract data from documents has been proven useful to a variety of businesses and is becoming increasingly widespread. The technology can help to generate short summaries, extract key information, and more. However, it’s worth keeping in mind the challenges and limitations of the technology like lack of consistency, difficulty with numerical data, etc. Anyway, the future of document analysis with ChatGPT seems promising.
Getting your project up and running is easier when you partner with the right team. With substantial experience in Generative AI, NLP, and ML, the Intelliarts team can assist you with the development of any complexity or with technical consulting.
FAQ
1. What types of documents can be processed with OpenAI GPT?
OpenAI GPT can process text-based documents like emails, articles, contracts, and reports. It is not designed for images or PDFs.
2. What languages are supported by document data extraction via OpenAI GPT?
OpenAI GPT primarily supports English but has some multilingual capabilities, though performance may vary for non-English languages.
3. How can I ensure the accuracy and reliability of data extraction with OpenAI GPT?
To ensure accuracy, validate GPT’s extractions with human review and iterative fine-tuning. It’s recommended to test extensively on domain-specific documents.
4. What business areas can benefit from using OpenAI GPT to extract data from documents?
Business areas like legal, healthcare, finance, customer service, and others can benefit from GPT’s capabilities to extract and summarize document information.
What is the best way for extracting data from an XML field?
The best GPT for extracting data from an XML field is a fine-tuned GPT model optimized for parsing and interpreting structured data. These models can efficiently handle XML elements, tags, and attributes, allowing for accurate extraction of data when combined with specialized tools and techniques like embedding models for better performance.