It’s estimated that the average person generates 1.7 MB of data per second. At the same time, an average company uses no more than 40% of its data, despite over 97% of business owners claiming they strive to be a data-driven company, and 79.4% of them are afraid that more data-wise companies will disrupt and outperform them.
The value of business data, its analytics, and the decisions made based on the generated insights are hard to overestimate. At the same time, AI brings advanced business automation capabilities fueled by data.
It’s more than interesting to delve deeper into the interplay of big data and AI strategies. In this post, you’ll read about real-life case studies of big data and AI, learn how they work together, what challenges and considerations should be kept in mind, and what the industry best practices for working with AI and big data are.
The interplay of big data and AI
In machine learning and deep learning, algorithms require vast amounts of data to learn and evolve, which is where a tech consulting company can provide valuable support. AI processes large amounts of data using distribution, big data analysis and consulting. This synergy enhances building, training, and testing models as well as operating them in real life based on business data.
Read also: Big data collection
Let’s explore the workflow of big data, available big data technologies, AI techniques, and, finally, into how artificial intelligence and big data analytics complement each other and produce the best outcomes:
Data collection, storage, and processing in big data are pivotal

Key processes and aspects of data collection, storage, and processing are fundamental for successful AI & big data solution implementation. Currently, there is a range of big data technologies that serve three main stages of working with big data. Let’s delve deeper into each stage and review the existing solutions for fulfilling them.
Data collection is the process of gathering and measuring variables of interest or just information, from varied sources. Instruments for collecting data include:
- Apache Flume: Distributed system for collecting, aggregating, and moving large amounts of log data from various sources to a centralized data store.
- Apache Kafka: Distributed streaming platform that functions as a messaging system, event store, and real-time stream processor.
- Logstash: Data processing pipeline that ingests data from multiple sources, transforms it, and sends it to destinations like Elasticsearch.
- Amazon Kinesis: Web service that offers real-time data processing over large, distributed data streams, used for real-time analytics.
- Google Pub/Sub: Real-time messaging service allowing reliable and asynchronous message exchanges between applications.
Data storage is the process of holding data in a digital format so it can be retrieved and used later. Instruments for storing data include:
- Hadoop Distributed File System (HDFS): File system that stores large volumes of data across multiple machines, providing high throughput and fault tolerance.
- Apache HBase: Non-relational, distributed database designed for quick access to large amounts of structured data.
- MongoDB: Document-oriented NoSQL database known for its scalability and flexibility in high-volume data storage.
- Amazon S3: Scalable object storage service for large-scale data storage, accessible globally.
- Google BigTable: Distributed, column-oriented data store for large-scale applications requiring significant data storage and low-latency access.
Data processing is the process of converting raw data into meaningful information through a series of computational steps. Instruments for processing data include:
- Apache Spark: Distributed system for big data workloads with libraries for SQL, machine learning, and stream processing.
- Apache Flink: Framework that processes stateful computations over data streams, known for high throughput and low latency.
- Hadoop MapReduce: Programming model that processes large data sets with a parallel, distributed algorithm on a cluster.
- Google BigQuery: Serverless data warehouse for scalable analysis over large datasets with SQL.
- Amazon Redshift: Petabyte-scale data warehouse service for analyzing data using standard SQL and BI tools.
It’s important to note that even a single big data pipeline is complex, and understanding its mechanism properly involves more than reviewing the detailed key phases. If you’re interested in delving deeper into big data components, types of big data pipeline architecture, and more, read another blog post by Intelliarts.
Enabling AI techniques and algorithms is crucial for effective big data utilization
Let’s proceed with reviewing common AI techniques and algorithms, followed by explaining how exactly big data can come in handy here:

AI techniques and algorithms are essential for leveraging big data in AI processes. As we can conclude, the listed algorithms and techniques require high-quality data in extensive quantities to be built and operate in the desired way. Big data is exactly what can support AI in this matter, and here’s how:
1. Providing training data is key to AI success
Big data offers a vast reservoir of information from which these algorithms can learn. The diversity and volume of datasets provided by big data allow AI models to capture a wide range of patterns, anomalies, and correlations that might not be apparent in smaller datasets.
2. Enabling model refinement is critical for AI accuracy
With access to big data, AI algorithms can continuously refine and improve their predictions and decisions. As more data is collected and analyzed, these models can be retrained or updated to enhance their accuracy. This iterative process is crucial in fields where precision is vital, such as healthcare diagnostics, financial forecasting, and autonomous vehicles.
3. Facilitating complex decision-making is where big data shines
Big data enables more sophisticated AI models by providing the necessary depth and breadth of data required for complex decision-making. For instance, when it comes to data analytics and machine learning, a large dataset can help identify more nuanced and accurate predictions, which wouldn’t be possible with limited data.
4. Enhancing personalization in AI is crucial for customer satisfaction
In customer-facing applications like marketing and e-commerce, big data combined with AI algorithms allows for a high degree of personalization. By analyzing extensive data on consumer behavior, preferences, and interactions, AI models can deliver highly personalized recommendations and experiences to individual users.
Now, as the relationship between AI and big data and the means of big data is clear, we can examine how large, high-quality datasets can enhance the performance of ML models and software solutions built on them.
Enhancing AI performance with big data is paramount for modern businesses
Here are three main ways in which big data can greatly improve the performance of AI-driven software solutions:
- Improving AI accuracy: Big data allows AI to recognize complex patterns and relationships through training on extensive, diverse datasets.
- Reducing bias: When AI models are trained on a broad range of data, they are less likely to exhibit biased behaviors or decisions.
- Enabling complex models: Complex AI models, such as deep learning neural networks, require massive amounts of data for effective training. Big data facilitates the development of these models by providing the necessary volume of training data.
Here are some examples of data that can be provided using big data to enhance AI solutions for various industries:

Read also about machine learning applications in insurance industry.
Challenges and considerations
There is a global discussion about the usage of AI and the solutions built with it. Gray Scott, a futurist and a techno-philosopher claimed:
“There is no reason and no way that a human mind can keep up with an artificial intelligence machine by 2035.”
Here are some concerns that are frequently raised in regard to the use of AI:
- Data privacy: Massive personal data collection risks breaches and unauthorized use. Ensuring ethical use and individual consent is challenging.
- Algorithmic bias: AI can reflect and amplify biases present in training data, leading to discriminatory outcomes.
- Lack of transparency: Many AI systems are complex “black boxes,” making it hard to understand their decision-making processes.
- Regulatory compliance: Complying with data protection laws like GDPR or HIPPA is challenging, requiring careful navigation of the legal landscape around data use.
- Ethical use and impact: Determining the ethical limits of AI use, particularly in areas impacting societal norms and individual lives, is a significant concern.
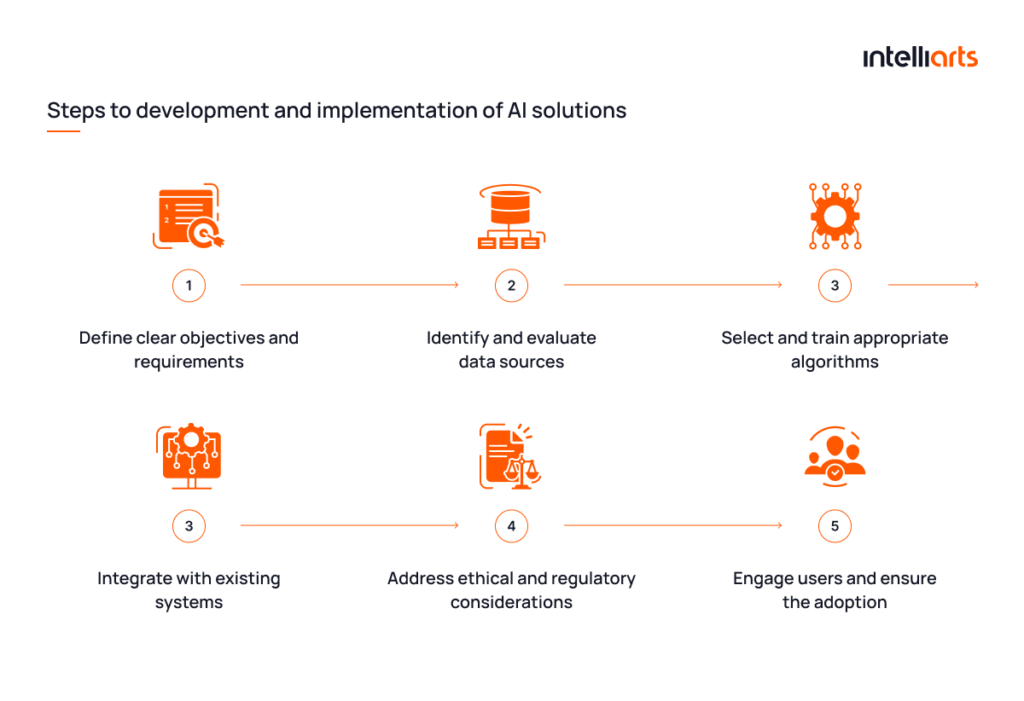
The listed concerns don’t indicate that AI shouldn’t be used. These are some of the modern-day challenges that are to be addressed as technology evolves and the approaches to its usage improve. One of the strategies for leveraging artificial intelligence wisely is shown in the infographic below:
Best practices for using AI with big data
As a company specializing in big data analytics and AI, Intelliarts sticks to and determines best practices for leveraging AI solutions reinforced with datasets provided by big data. Some of the points we would like to highlight in that regard are:
Prioritize data quality, diversity, and governance
This means ensuring the data is accurate, complete, and consistently formatted. Diverse data sources also matter; they prevent biases and improve model generalization. Implement a strict data governance policy, which involves:
- Regular data audits
- Clear data sourcing
- Strict privacy controls
Remember that the quality of your AI predictions depends heavily on the quality of the data you feed into your models.
Ready to adopt AI and big data?
Reach out to Intelliarts’ experts to kickstart your AI journey today.
Contact us
Foster a culture of experimentation and model iteration
In AI development, being open to experimentation and continuous model iteration is key. This involves:
- Regular model updates with new data sets
- Testing different algorithms
- Tweaking parameters
Encourage your team to view failures as learning opportunities. In our projects, we run A/B tests to compare different models and use the insights to refine our approach. This continuous loop of experimentation and learning is what keeps your AI models relevant and effective.
Always strategize for scalable infrastructure
We know well that scalable infrastructure is not a luxury but a necessity. As the stream of data grows, your infrastructure needs to evolve with it.
As our recommendation, opt for cloud solutions for flexibility or invest in distributed computing for handling large datasets and intensive computations. Scalability ensures that your infrastructure won’t become a bottleneck when the AI models become more complex.
Align AI initiatives with real-world applications and business goals
AI shouldn’t exist in a vacuum. Aligning AI initiatives with real-world business objectives has always been key to creating impactful solutions. This means understanding the business context deeply and identifying problems that AI can effectively solve.
So, the development should be all about building solutions that aren’t just technically sound but also deliver tangible business value, whether it’s through process optimization, enhancing customer experiences, for example by using AI recruitment software for hiring, or driving innovation.
Emphasize compliance and security
In today’s world, overlooking compliance and security in AI can lead to serious consequences. As such, the EU proposed AI rules violations that will result in fines equal to up to 6% of a company’s global turnover.
From personal experience, integrating strong security protocols and ensuring compliance with data protection laws from the start of your project is non-negotiable. This includes regular security audits, data encryption, and adhering to standards like GDPR. In the long run, this doesn’t only protect your projects but also builds trust with your users, a crucial element in the success of any AI application.
The Intelliarts experience with AI and big data
Here at Intelliarts, we are proficient with both AI-driven and big data strategies and solutions. Some of our related cases include the following:
DDMR data pipeline case study

The challenge was to streamline data acquisition from Firefox and enhance the efficiency of handling extensive clickstream data. This was crucial since the company’s revenue generation, particularly in its sales department, heavily relied on the effective management of big data.
The solution was the creation of a specialized browser application coupled with a comprehensive data management pipeline encompassing aspects like data gathering, storage, processing, and distribution. The project scaled impressively, evolving from a nascent stage to managing clusters equipped with 2000 cores and 3700 GB of RAM. As a result of this collaboration, our client experienced a significant surge in yearly revenue.
Discover additional details about how Intelliarts built a big data pipeline from another of our blog posts.
Real estate company case study
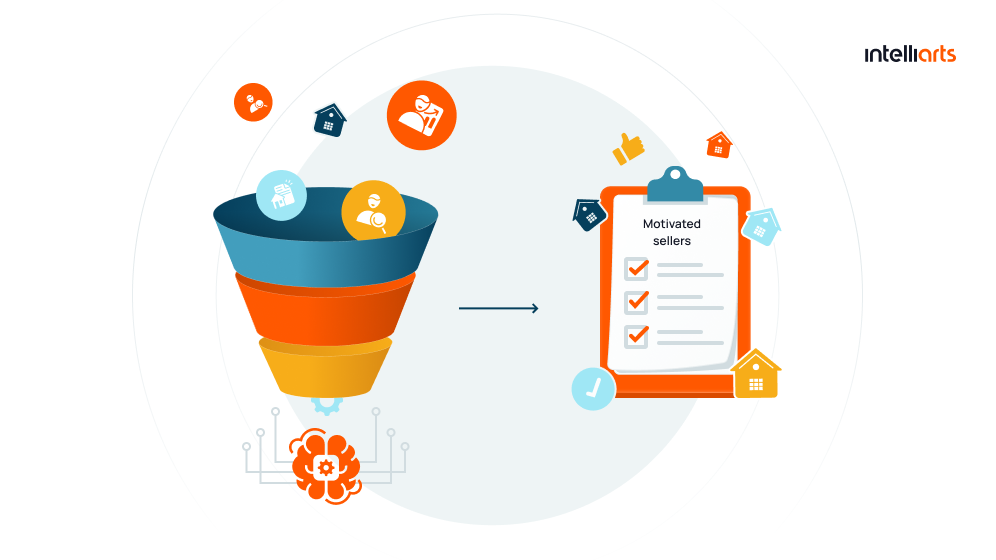
The challenge was to accurately forecast which homeowners were likely to list their properties for sale, preempting the actual market listing. The company was analyzing a vast array of over 1400 property and demographic variables across an extensive database exceeding 60 million records. Efficient processing of this voluminous raw data was imperative.
The solution entailed relocating the data to Amazon S3 storage, executing data transformation, and leveraging AWS Glue for data processing. The resultant model successfully predicted approximately 70% of potential home listings, a figure significantly higher than the industry standard.
Final take
Big data provides the vast, diverse datasets required for AI algorithms to learn and make informed decisions, while AI offers advanced analytical capabilities to extract meaningful insights from large and complex datasets. AI works with big data well and the potential of their combined power is immense, promising significant advancements in different industries.
Building from the ground up and integrating into the existing infrastructure an AI solution powered up with your business data is a challenging task. It should be trusted to engineers with a deep expertise in AI and ML only. Consider partnering with Intelliarts, as a big data consulting company. Our team will help you get the most value from your big data.
FAQ
1. Can small businesses benefit from big data and artificial intelligence? How?
Small businesses can leverage big data and AI for targeted marketing, customer insights, and operational efficiencies. These technologies enable them to compete with larger firms by making data-driven decisions and personalizing customer experiences.
2. How does big data AI impact consumer privacy and security?
Big Data and AI pose privacy and security risks by potentially exposing sensitive personal information. Ensuring data security and ethical AI use is crucial to protecting consumer rights and maintaining trust in digital ecosystems.
3. What future trends are expected in the convergence of big data and AI?
The future of big data and AI includes increased automation, advanced predictive analytics, and more sophisticated AI algorithms. Enhanced integration will lead to smarter, more adaptive technology solutions across various industries, revolutionizing how data is analyzed and applied.