

Computer vision technology brings many opportunities, including the replacement of manual inspection to a certain extent. That’s why the Intelliarts team found it promising to start working on an automated car damage assessment project.
Let’s have an in-depth look at how to solve AI damage detection tasks using computer vision from the experience of the Intelliarts team of ML engineers, what particular algorithms can be used, what the process of training and evaluating a model for detecting visual damage on a car is, and what popular algorithm may produce better outcomes in a computer vision project.

AI car damage assessment vs. car damage detection
Let’s start with the difference between car damage detection and car damage assessment when powered by computer vision.
Car damage detection focuses on recognizing the presence of damage and identifying damaged areas. In contrast, car damage assessment goes a step further — it evaluates the extent and cost of vehicle damage based on identified damage with the prospect of making repair decisions.
Basically, car damage detection is a core part of the broader car damage assessment.
In traditional workflows, car damage assessment is often closely connected to a large load of manual document processing and property damage assessment. Insurance companies, for example, may experience a high volume of vehicle damage claims, especially during peak seasons. That’s exactly when AI-powered vehicle damage inspection app solutions come into play, offering automated support to speed up the process.
Computer vision algorithms process post-accident vehicle imagery. Smart systems can recognize a car validating whether it’s the same one as in document evidence. They can also identify damaged car elements and estimate preliminary damage and repair costs.
While the conventional workflow is complicated and time-consuming, AI damage detection includes only 4 steps:
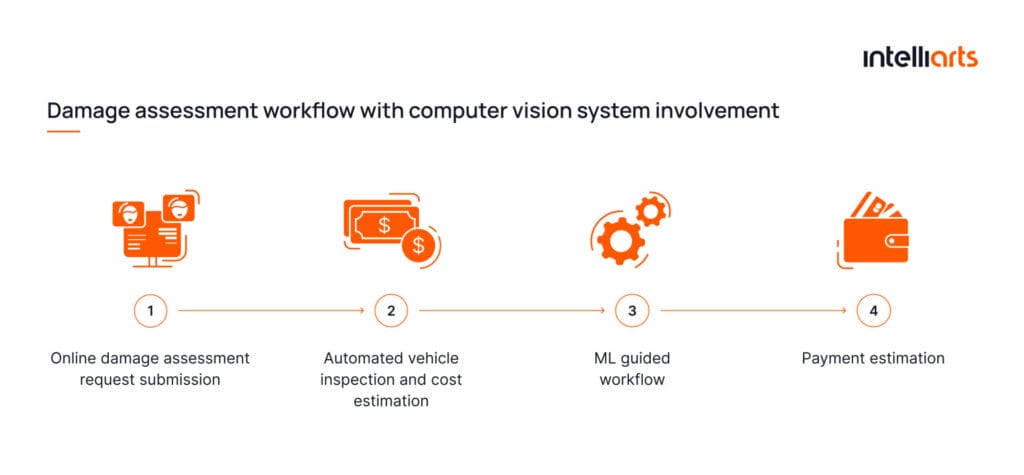
Building a well-performing AI car damage recognition system may be complex. Don’t hesitate to reach out to reach out to our team of well-seasoned AI engineers should you need assistance.
Computer vision-assisted vs. manual car damage assessment
While manual vehicle inspection is prevalent, computer vision-assisted one gradually becomes complementary to it. In some cases, it even completely replaces assessment by a human worker. Let’s have a look at the most significant pros and cons of both types of car damage detection.
Main pros and cons of computer vision-powered car damage detection
AI damage assessment has the following strengths to offer:
- Workforce use and safety. With AI technologies, human involvement in the vehicle inspection cycle can be minimized. It results in better worker safety as inspectors are not vulnerable to risks associated with assessing car damage manually, such as electrical or chemical exposure hazards, moving parts, slip and fall.
- Cost savings. Automating simple insurance claim processing can lower operating costs. After all, everyday cases like scratches or glass cracks are easy to handle for the AI system, yet time-consuming for human inspectors.
- High efficiency. Typically, it takes a computer vision system only a few seconds to process a single image. It makes working with batches of images incredibly time-efficient, allowing for more inspections to be completed in less time.
- Accuracy. In contrast to manual assessments, which rely on human judgment and are prone to inconsistencies and errors, AI systems offer greater accuracy. Moreover, some types of damage, such as hidden flood damage, may not be easily detected through conventional means. AI-powered car scanning and inspection for a flooded car helps bridge this gap by using specialized algorithms to identify water-related damage that could be hidden beneath the vehicle’s surface.
Here are two limitations of computer vision systems for car inspection:
- Accuracy depends on the image quality. Low image sharpness or inappropriate lighting may largely deteriorate image processing. Besides, there are still risks of vehicle owners intentionally making fake images or taking photos in the way it alters the view of the severity of the damage.
- Some types of damage cannot be detected. In the case of deteriorations that don’t categorize as glass or metal ones or are hidden damages, image processing may not be enough for an accurate estimation. AI damage detection heightens risk of fraud, but engineers may mitigate the issue by applying additional fraud-detection algorithms.
Main pros and cons of manual car damage detection
The strengths manual vehicle damage assessment is appreciated for are the following:
- High reliability in specific cases. Trained inspectors can quite accurately estimate the severity of deterioration and the potential repair costs. They also can spot hidden damages, making it better for cases of inspection of flooded or extensively used vehicles.
- Widely used approach. Since manual vehicle inspection is recognized as an industry-standard approach, finding specialists and establishing the optimal workflow should not present a difficulty.
Here are two limitations of the conventional approach to vehicle damage detection:
- High rate of labor resource usage. In the conventional inspection cycle, manual labor is involved in nearly every step. It increases the probability of human error as well as brings difficulties related to human resource management.
- Time-extensive procedures. Both document approval and manual car damage inspection take considerable time. This way, a single claim completion may take days or weeks.
Let’s summarize the key points of both AI damage detection techniques and compare them against each other.
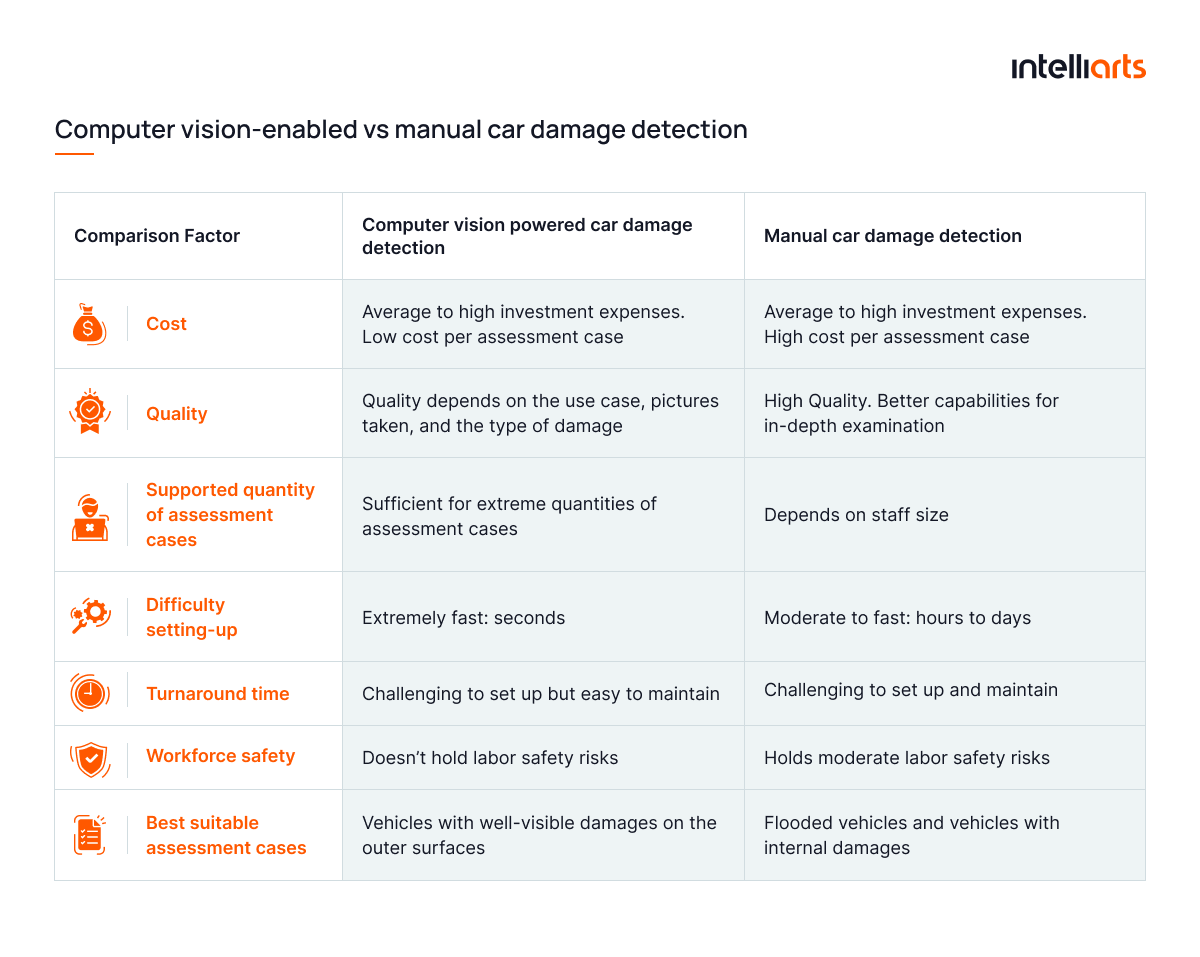
AI damage detection will unlikely completely replace the manual one in a short while. Yet, its capabilities are enough to take on large batches of assessment cases. It’s also interesting to know how machine learning optimizes insurance claims processing, as one of the 5 machine learning applications.
Types of car damage to be detected with computer vision for vehicle defect detection
During the AI car damage inspection, algorithms use digital vehicle images to detect the following types of damage:
Metal damage
Deteriorations of the bumper, hood, doors, dickey and other metal car parts are classified as forms of metal damage:

- Dents and deformations. Concavity on the metal surface caused by pressing the metal body inside is known as a dent. It’s often caused during car crashes when there is destructive pressure from external objects.
- Scratch. When a hard or sharp object is moved against a metallic surface, it causes scratches. It’s the most prevalent type of car damage, and it may largely vary in its severity.
- Tears. If a vehicle sustains extreme forces, the metal parts may be split into pieces. This damage is called a tear. It often affects the external surface of a car part as well as results in extra destruction to the inside of the car.
Metal damages are quite easy to detect, as they are well-visible. Scratches, being the most common type of surface defect, are a major focus of computer vision models. Advanced techniques in computer vision for scratch detection enable AI to assess the size, depth, and severity of scratches with high precision.
At the same time, the tricky part is the assessment of the destruction’s magnitude. Using deep learning techniques in computer vision allows the system to solve even such complex tasks.
Glass damage
Deteriorations of the windshield, back glass, car windows, headlight, and taillight are classified as forms of glass damage:

- Crack. This surface damage may be caused by physical forces, extreme temperatures, weather conditions, extreme pressure, or combinations of these factors. It typically looks like a net of circles and lines that indicate surface areas where the glass integrity was compromised.
- Chip. When a small chunk of glass comes out of the surface, it’s called a chip. Professionals refer to it as a “stone break” or “pit.” This damage doesn’t penetrate the glass of the way, and consequently, it doesn’t cause longer cracks.
- Spider crack. If there was a heavy physical impact caused to glass by an object, like a rock, a spider crack is formed. It often looks like a small hole in the center, where the force was applied — an impact point. Multiple cracks are formed around this area, giving the glass surface the appearance of a spider web.
Usually, the severity of glass destruction can be both spotted and assessed quite accurately.
Other damage
 Damages that are not categorized as either metal or glass damage or are not forms of impact damage fall within this definition. Examples include dislocation or replacement of car parts, gaps between car parts, missing parts, cosmetic damage done, for example, to car paint, and more.
Damages that are not categorized as either metal or glass damage or are not forms of impact damage fall within this definition. Examples include dislocation or replacement of car parts, gaps between car parts, missing parts, cosmetic damage done, for example, to car paint, and more.
The capabilities of computer vision algorithms to spot non-destructive damage are limited, but they still may have something to offer.
What algorithms can solve car damage detection tasks?
For AI damage detection, engineers utilize the image segmentation algorithm. Its work is to attribute one or another class to a particular pixel in the image based on certain visual characteristics, such as color, texture, intensity, or shape. In the case of vehicle inspection, the class is either with damage or without damage. In AI vehicle damage inspection, the goal of image segmentation is to simplify or change the representation of an image into a more meaningful form and separate objects from the background to analyze it easily.
So what’s the difference between instance and semantic segmentation? The two major approaches are the following:
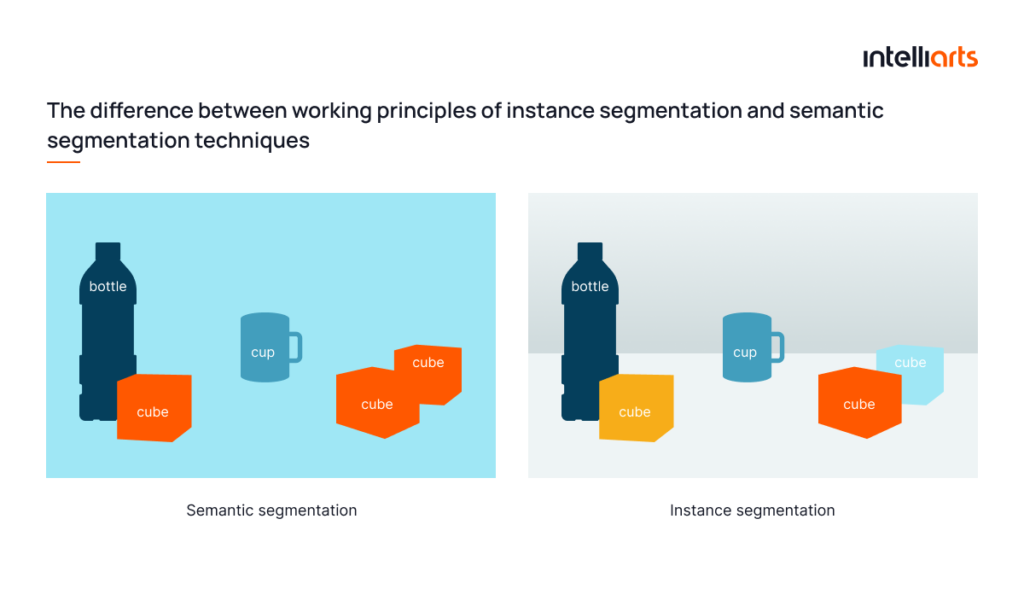
Instance segmentation
With this computer vision technique, each individual object is identified and labeled with a unique identifier. The first step of instance segmentation is object detection. In this phase, a computer vision algorithm attempts to detect all objects in the image and provide a bounding box, i.e., rectangular or square-shaped figure surrounding an object, to each of them. During the car damage detection and classification done over areas inside bounding boxes, the algorithm calculates the confidence or the likelihood of the particular object of interest with a specific class, e.g., car, tree, human, etc., being inside the bounding box.
In the second step of the technique, the algorithm performs segmentation in each of the bounding boxes and labels each pixel, indicating whether it belongs to an object or not.
Another requirement of instance segmentation is the usage of pixel-wise masks. These are binary images that are used to identify the location of objects or regions of interest within an image. Each pixel in the mask is assigned a value of either 0 or 1, indicating whether that pixel belongs to the object or region of interest. Pixel-wise masks can be generated manually by annotating images.
The way this algorithm works ensures that multiple instances of the same object are differentiated from one another, even if they overlap or are partially obscured by other objects in the image.
Semantic segmentation
The semantic segmentation technique involves dividing an image into multiple segments, each of which corresponds to a particular object or region of interest within the image, and classifying them separately. Unlike traditional image segmentation methods that simply partition an image into arbitrary regions based on pixel similarity, semantic segmentation aims to associate each segment with a meaningful semantic label, such as a person, car, building, tree, etc.
Semantic segmentation treats multiple objects belonging to the same class as a single entity. It can indicate boundaries of, for one, all people, all cars, or all buildings in the image, if necessary. It’s important to note that semantic segmentation allows for detecting damages only without distinguishing them. In contrast, instance segmentation can distinguish multiple distinct damages from each other.
Once trained, the semantic segmentation model can be used to segment new images by propagating them through the network and generating a pixel-level segmentation mask. The latter works similarly to pixel-wise masks in instance segmentation yet assigns a label to each pixel in an image instead of generating multiple masks, one for each instance of an object.
Instance segmentation vs. semantic segmentation based on real-life observation
While both approaches play important roles in AI damage detection, the choice of method depends heavily on the project’s goals and requirements. At Intelliarts, we have hands-on experience evaluating different AI models for vehicle damage detection tasks.
Let’s explore some real-life AI architectures that have proven effective in practice.
Mask R-CNN
- Mask R-CNN (Region-based Convolutional Neural Network with masks) is a deep learning architecture for object detection and instance segmentation. It’s built upon the Faster R-CNN object detection model and has a segmentation part, i.e., a subset of layers operating on the input data.
- Mask R-CNN works in two stages. In the first stage, it generates region proposals using a Region Proposal Network (RPN), which suggests regions of the image that are likely to contain objects. In the second stage, it performs object detection and segmentation by simultaneously predicting class labels, bounding boxes, and masks for each proposal.
U-Net
- U-Net is a convolutional neural network architecture designed for image segmentation tasks. It’s incredibly popular for solving medical image segmentation tasks such as brain tumor segmentation, cell segmentation, and lung segmentation. It has also been adapted for other image segmentation applications, such as road segmentation in autonomous driving.
- The U-Net architecture has a distinctive “U” shape, which is formed by the downsampling and upsampling operations. The network has a contracting path, which captures context and downsamples the input image, and an expansive path, which enables precise localization and upsamples the feature maps. In essence, the network can retrieve detailed information about the objects being segmented while also capturing the context and global structure of the image.

In our recent research, the Intelliarts team tested the two popular neural network architectures used for image segmentation tasks — Mask R-CNN (for instance segmentation) and U-net (for semantic segmentation). Both computer vision algorithms were trained and then tested using the same car damage image datasets. We used precleaned and prepacked data from the publicly available Coco car damage detection and the Segme image datasets.
Despite the fact that Mask R-CNN has a more complex architecture and processes the region proposals rather than the entire image, testing revealed that actually, U-net, as a semantic segmentation-based algorithm, performs better.
U-net showed optimal outcomes in the first part of the test when the AI algorithms were used for identifying car damages and evaluating their magnitude. Besides, in the second part, when Intelliarts engineers made the computer vision models identify damaged car parts and recognize them, Mask R-CNN performed better as well. It brought our team to the conclusion that the semantic segmentation model, particularly the tested U-net, is currently a better choice when it comes to a vehicle damage inspection.
You may give a try to an online demo that presents an interactive playground for the trained AI damage detection model. The demo shows the capabilities of a computer vision-enabled model to detect car damage based on an input image or video frame.
The two-model AI solution by Intelliarts
Intelliarts engineers built a software solution composed of two AI models, one of which is used for AI car damage detection and the other one for car part detection. So, when a user inputs a damaged car’s image in the resulting solution, it indicates the damage and identifies the affected car part separately. As a result, the report generated by the system can specify outcomes like “left door — dent” or “front bumper — scratch.” The outcomes are then compared against similar cases in a prepared image database with repair cost estimations.
The success of this approach also relies on how to fine-tune the model for car damage detection, ensuring both models work together to offer accurate damage classification and assessment of repair costs. In this context, insights from a totaled car value calculator can naturally complement the analysis by helping frame discussions around whether repair costs outweigh the vehicle’s overall worth.
The finished car damage software solution is capable of recognizing particular car parts, detecting and categorizing multiple types of damage, such as metal or glass damage and dislocation or replacement of car parts. The solution helps to capture damaged parts of the vehicle and evaluate the value of repairs costs needed, as well as to assess the severity of the damage. The functionality of a trained AI model should be enough to solve most of the simple car damage insurance claims with little human supervision.

For product owners, the end goal of computer vision projects is to get business benefits that include the following:
- Cost optimization. Automated detection can be done at a much lower cost compared with manual inspection, resulting in significant savings for insurance companies.
- Reduction of labor-intensive tasks. Automating the lion’s share of car inspection cases can reduce the workload for insurance company staff and allow them to focus on other critical tasks.
- Improved accuracy. Automated systems can analyze images of the car with greater precision, identifying even small damages that may have been overlooked by human inspectors.
- Faster claim processing. Automated damage detection can speed up the claim-processing time, enabling insurance companies to settle claims faster. This may result in improved customer satisfaction and retention rates.
Partnering with a trusted ML service provider is half the success when it comes to implementing a complex computer vision project.
Final thoughts
Vehicle inspection is one of the resource-intensive tasks in traditional workflows. Businesses may use automated car damage inspection powered by AI to streamline claim processing when car damage detection is involved. The image segmentation algorithm is what can perform such tasks. Yet, it’s necessary to carefully choose an optimal neural network, which may be Mask R-CNN, U-net, or any other, to build a model on, train a model properly using data annotation techniques, and then estimate its performance.
Solving motor damage assessment through AI and other computer vision tasks requires strong expertise and substantial experience in the AI field. Here at Intelliarts, we have already assisted a number of customers by delivering well-performing AI systems. Should you need assistance with computer vision implementation or other areas of machine learning — feel free to reach out, our insurance software developers are ready to assist you.
FAQ
1. What types of data are used to train the computer vision models?
You can use labeled images, video frames, augmented data, 3D scans, and infrared imagery.
2. In which industries and applications can a two-model car damage detection solution be used?
Examples of domains include auto insurance, car rentals, auto repair, vehicle inspections, fleet management, and used car sales.
3. How can I explore or implement a two-model computer vision solution for car damage detection in my project or business?
Having a demo of this you can gather diverse datasets for fine-tuning, select complementary architectures, integrate into workflow, and continuously evaluate performance to finally have your best two-model-based solution.








![Implementing Object Detection in Business [Case Study]](https://intelliarts.com/wp-content/uploads/2021/11/65e54c_b4be1b6c2d04466a9bdc4c8246183a8amv2.webp)