


To implement machine learning for predictive maintenance, we recommend starting by collecting and preparing high-quality sensor and maintenance data and then choosing suitable algorithms based on whether labeled failure events are available. Also, consider starting with a proof of concept to validate the approach before scaling to full deployment across assets.
Discover the power of machine learning techniques for predictive maintenance. Learn how advanced predictive maintenance algorithms can reduce downtime and optimize equipment performance.
Predictive maintenance using machine learning is an effective way to minimize downtime, extend asset life, and cut costs across industries. Unlike reactive or preventive approaches, this method uses sensor data and algorithms to anticipate failures before they happen. At Intelliarts, we have over 5 years of experience applying supervised and unsupervised predictive maintenance techniques to real-world challenges, from manufacturing to e-mobility. A good example is our asset failure prediction case study, where machine learning algorithms for predictive maintenance helped detect faults early and improve maintenance planning.
Depending on business needs and data available, predictive maintenance (PdM) can be approached with supervised, unsupervised, or hybrid methods. Even when companies lack detailed maintenance records, raw sensor data can still be leveraged to uncover anomalies and degradation patterns. In this article, we’ll walk through the main machine learning techniques for PdM, their pros and cons, highlighting how each can be applied in practice and what trade-offs to consider.
We can solve the PdM problem using one of the following machine learning (ML) techniques:
-
Supervised learning – requires labeled failure events to be present in the dataset
-
Unsupervised learning – we can use data that doesn’t contain labeled failure events

Based on the company’s maintenance policy, maintenance information may not be collected at all, which might not be the best option if a supervised-based predictive maintenance maintenance machine learning project is planned sometime in the future. But if the company has collected at least raw data from the equipment sensors it still might be used in a combination with unsupervised predictive maintenance approaches.
Supervised learning based PdM
The most important factor in the success of a robust and precise ML-based predictive maintenance system is the quality of data. So, if we have enough information about maintenance situations in collected data, supervised machine learning is the way to go. Additionally, supervised machine learning problems can be also divided into regression problems (when output assumes continuous values) and classification problems (when output assumes categorical values).
For a practical application of these concepts, explore our case study on solar panel fault detection, which demonstrates the effectiveness of ML techniques in identifying and preventing faults in renewable energy systems.
Three essential maintenance data sources are required to qualify a problem for a supervised predictive maintenance project:
The complete fault history
When you build a solution that leverages predictive models to make forecasts on failures, it is crucial for an algorithm to have an opportunity to learn and train on both normal operating state and operating during failures. There must be enough training data and a sufficient number of examples in both categories to enable the ML models to work properly.
The detailed history of maintenance and repairs
Having enough maintenance information is mandatory for a PdM solution. The model should be aware of all replaced components and fix resolution.
Machine conditions
It is important that available data contains time-varying functions that include aging patterns and anomalies that are able to cause a performance reduction. We are assuming that the health status of a particular machine is decreasing constantly, and it is possible to calculate specific metrics (hours, miles, etc.) before the failure happens.
Unsupervised learning based PdM
When information about previous equipment maintenance is not available in data, we can still build a predictive maintenance solution using unsupervised machine learning techniques, which could be used to detect anomalous behavior of equipment.
The overall complexity of the PdM problem may vary. Depending on that, predictive maintenance challenges can be solved with the help of traditional machine learning algorithms or deep learning algorithms. We will talk exclusively and in great detail about deep learning in the next article, but for now, let’s focus on the value traditional ML techniques can bring, particularly predictive maintenance algorithms.
Learn about another field where machine learning is transforming industries, allowing for faster and more accurate vehicle assessments in insurance and repair sectors – AI car damage detection.
Traditional machine learning techniques for predictive maintenance
Decision trees
This is probably one of the most powerful tools for prediction and classification. It looks like a tree structure, where each internal node denotes a test on an attribute, the outcome of the test is being represented by each branch, and each leaf node (terminal node) holds a class label.
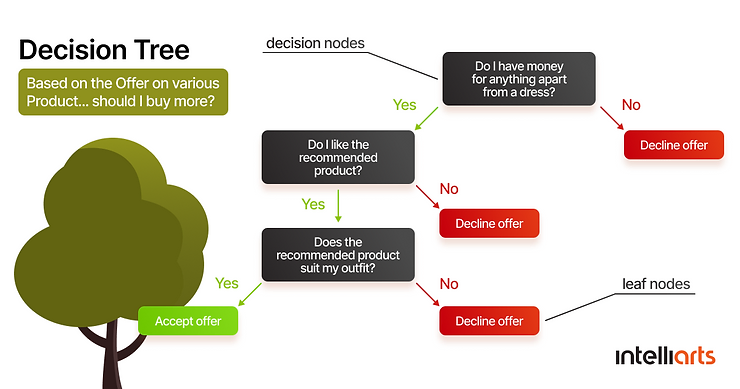
To build a tree, we need to divide a source set into subsets based on the attribute value test. This is a repeatable process for each derived subset in a recursive manner and is called recursive partitioning. When the subset at a node has the same value of the target available, or in a case when splitting no longer adds value to the forecasts, the recursion is considered complete. You don’t need any domain knowledge or parameter setting to build a decision tree classifier, hence it’s suitable for exploratory knowledge discovery.
At Intelliarts, we’ve seen decision tree–based methods work especially well in early-stage PoCs, where interpretability is important and quick wins can help validate the best model for predictive maintenance before moving to more advanced ensemble methods. To further ensure the reliability of these early-stage models, incorporating the Momentic AI software testing tool alongside platforms such as Testim, Functionize, or Cypress, helps teams validate complex ML-powered applications by testing data flows, system behavior, and edge cases before failures impact production.
How to use trees in PdM?
There are plenty of interesting use cases, let’s focus on two of them.
Case 1: Fault diagnosis and detection in grid-connected photovoltaic systems (GCPVS)
GCPVS are electricity-generating solar PV power systems that are connected to the utility grid. A grid-connected PV system consists of solar panels, one or multiple inverters, a power conditioning unit, and grid connection equipment. The grid-connected PV system supplies the excess power, beyond consumption by the connected load, to the utility grid, saving on the electricity bills for the customer. However, without proper maintenance, the whole point of these devices will be missed, because they won’t operate correctly.
According to the case described by Rabah Benkercha and Samir Moulahoum, a decision tree algorithm was used to detect faults in GCPVS. To complete this goal, a non-parametric model was implemented to forecast the state of GCVPS, and the dataset was collected from GCPVS by the acquisition system in different weather conditions. The data used for model training consisted of three numerical attributes and two targets.
The attributes included:
-
Temperature ambient
-
Irradiation
-
Power ratio (calculated from measured and estimated power)
The targets included:
-
Healthy or faulty state for detection
-
Four classes of labels for diagnosis: free fault, string fault, short circuit fault, or line-line fault
Additionally, the Sandia model was chosen to estimate the power produced by GCPVS during the healthy state of operation (in 2015 Sandia has developed a software toolkit that uses stochastic programming to perform power system production cost model simulations, which was named PRESCIENT). All collected data was split into two parts, 66% of which were used for learning and the remaining part was used for testing.
The new data was recorded for five days in total in order to evaluate both models robustness and efficiency. The results were very impressive, as the decision trees model used for the diagnosis task was able to reach 99.80% of accuracy. The Sandia model evaluation showed high prediction accuracy, with the correct classification number being close to 100%.
Case 2: Determining RUL of lithium-ion batteries
Another interesting case of leveraging decision trees is finding out the remaining useful life (RUL) of lithium-ion batteries. These batteries can only be used in specific conditions and require a battery management system (BMS) to monitor the battery state to ensure the safety of the operation.
Multiple machine learning techniques for predictive maintenance were applied to deal with RUL challenges, but they faced the following limitations:
-
The extracted features didn’t reflect the information hidden in the historical degradation status
-
Nonlinearity caused imprecise OR low accuracy of battery degradation prediction
One of the options to solve this was to combine the time window (TW) and gradient boosting decision trees (GBDT). In this method, the energy and fluctuation index of voltage signals were being verified and chosen as features. After that, a time window-based method was used to extract features from the historical discharge process. The next step was to adopt gradient boosting decision trees for modeling the relation of features and remaining useful life. This method has proven results to solve this problem.
Support vector machines (SVM)
This is a model that fits great for classification and regression problems. It can solve linear and non-linear problems and works well for a variety of other real-world problems. The algorithm creates a line or a hyperplane which separates the data into two classes:

The key idea of this algorithm is to find a hyperplane in N-dimensional space (in which N represents the number of features) that distinctly classifies the data points. Among two classes of data points, a lot of possible hyperplanes can be chosen. The goal is to find a hyperplane with a maximum margin, or the maximum distance between data points of both classes. The future data points can be classified with more confidence when the margin distance will be maximized.
In our work, we’ve found SVMs to be particularly effective when datasets are smaller but still require high accuracy. For PdM, they are a practical option for both anomaly detection and direct RUL estimation, especially when interpretability is needed. To provide you with context, let’s review some applications of SVM in predictive maintenance.
Case 1: Fault detection and diagnosis of chillers
The first case is a classification problem that implements fault detection and diagnosis (FDD) of chillers. The chillers are used in buildings to provide cooling and are often the most energy-consuming piece of equipment.
In one of the cases, the least squares support vector machine (LS-SVM) model was additionally optimized by cross-validation to leverage FDD on a 90-ton centrifugal chiller. To achieve the goal, three system-level and four component-level faults were analyzed. A detailed discussion was conducted to validate and employ eight fault-indicative features extracted from the original 64 parameters. Compared with the other two machine learning methods used in this project, the LS-SVM model showed better results in the following parameters, especially those on the system level:
-
overall diagnostic efficiency
-
detection rate
-
false alarm rate
The prediction precision was quite impressive, with refrigerant leak/undercharge (99.59%), refrigerant overcharge (99.26%), and excessive oil (99.38%).
Case 2: Another RUL estimation
Going back to remaining useful life estimation, there was a case when it was needed to estimate the RUL directly from sensor values, without estimating degradation states or failure threshold. Sometimes it is important to be able to estimate RUL at any stage of the degradation process.
To achieve this goal, a direct relation between sensor values was modeled with the help of support vector regression (SVR). This is the most popular approach for fault prognosis. The experimental results showed that the SVR approach is a viable alternative to the existing methods. Not only RUL can be estimated at any point of the degradation process, but also an offline wrapper variable selection can be applied before training the prediction model (which reduces computational time and increases accuracy).
Case 3: Anomaly detection in EV charging systems
The Intelliarts team applied machine learning algorithms for predictive maintenance in a project with EV Connect, a leading EV charging provider. Their goal was to reduce unexpected outages and prepare for a predictive maintenance solution to improve service reliability.
Our team analyzed large volumes of historical data collected via the OCPP protocol and stored across MongoDB and ElasticSearch. After cleaning and transforming the raw inputs into a structured format, we applied unsupervised anomaly detection algorithms such as DBSCAN, Isolation Forest, and Local Outlier Factor. This helped identify abnormal behaviors, including unusually long charging sessions, that pointed to risks in station performance.

Together with the customer’s experts, we interpreted these anomalies from a business perspective and delivered recommendations on improving data pipelines, automating labeling, and collecting the right raw inputs. This provided EV Connect with strategic insights into charger usage patterns and laid the foundation for building a full predictive maintenance machine learning project in the future.
K-Nearest neighbors algorithm (KNN)
This is a supervised machine learning algorithm in predictive maintenance that can deal with both classification and regression problems. KNN algorithm works in the way that similar data points are close to each other. The algorithm finds the distances between a query and all the examples in the data and selects the specified number of examples (K) closest to the query. After that, the algorithm votes for the most frequent label, if we talk about classification. For the regression problem, the averages of labels are being calculated. When the new data appears, it is classified in one of the categories. Let’s say we have Class A, Class B, and the new unknown data point “?”. This data point is classified by a majority vote of the neighbors and assigned to the class most common amongst its K nearest neighbors, which is measured by a distance function.

In other words, KNN is all about similarity (also known as closeness, distance, or proximity) and calculating the distance between points on a graph. This method is simple yet effective, though it can become computationally heavy with large datasets. At Intelliarts, we’ve used KNN-based approaches as part of ensemble pipelines to benchmark performance and provide a fast baseline for more complex models. Moving to practical implementation in predictive maintenance, there are a few cases worth our attention:
Case 1: The diagnosis of electric traction motors
First, the automotive industry has a wide application for electric traction motors. The operational conditions of these motors could be characterized by variable load, rotational speed, and other external conditions which complicate the process of diagnosing bearing defects. Because of this, there is a challenge for detecting the onset of degradation, isolating the degrading bearing, and making a classification of defect types.
This is a classification problem that was solved by leveraging a diagnostic system built based on a hierarchical structure of K-nearest neighbors classifiers. Previously measured vibrational signals were used as input. The bearing diagnostic system was done by an approach that was based on multi-objective (MO) optimization that integrates a binary differential evolution (BDE) algorithm with the KNN classifiers. While this approach was applied to the experimental dataset, the results showed the capabilities of this method to solve the issue.
Case 2: Improving the reliability of insulated gate bipolar transistor
As an example of a regression problem, we can talk about an insulated gate bipolar transistor (IGBT), which is a great performance switching device commonly used in power electronic systems. However, there is a challenge in ensuring reliability and safety for IGBT, which KNN can solve.
There is an innovation in this field, as a new prediction model with a complete structure based on an optimally pruned extreme learning machine (OPELM) and Volterra series is recommended to predict the remaining useful life of insulated gate bipolar transistor and forecast its degradation. We can refer to this model as the Volterra k-nearest neighbor OPELM prediction (VKOPP) model. The model needs the minimum entropy rate method and Volterra series to rebuild phase space for IGBT’s aging samples. The new version of the algorithm can effectively reduce the negative impact of noises and outliers and is used to establish the VKOPP network. To successfully forecast remaining useful life for the IGBT the combination of the K-Nearest Neighbors method and least squares estimation (LSE) is leveraged to calculate the output weight of OPELM.
Compared to the classic prediction approaches, the prognostic results show that this one can predict the RUL of IGBT modules with small error, lower time spending, and significantly higher precision.
Case 3: Failure prediction in manufacturing equipment
A global manufacturer of home appliances partnered with Intelliarts to address frequent equipment breakdowns on the factory floor. These failures resulted in costly downtime, repair expenses, and shipping delays, so the company decided to build an asset failure prediction solution that could forecast issues before they occurred.
Intelliarts analyzed large volumes of historical and real-time IoT sensor data from the production line, transforming it into a format suitable for ML modeling. After testing multiple predictive maintenance algorithms, we found that an Extreme Gradient Boosting classifier delivered the best performance. With proper feature engineering, clustering, and model tuning, the solution achieved more than 90% accuracy in forecasting system failures.
The project helped the manufacturer cut maintenance costs by 5% and improve production line efficiency. Most importantly, the company gained the ability to predict which parts were most likely to fail and maintain or replace them just in time. In the end, this helped reduce downtime while ensuring consistent quality standards.

Advantages and disadvantages of the mentioned algorithms
Obviously, there is no single perfect approach to solving each particular challenge. Each algorithm that we mentioned in the article, has its best area for implementation. Let’s take a look at the pros and cons of each specific algorithm.
Decision trees
Advantages:
-
Significantly less effort in data preparation during pre-processing phase compared to other algorithms
-
Do not require data normalization
-
Do not require data scaling
-
Missing values are not a major or disrupting problem for building a decision tree
-
Very intuitive and easy to understand and explain to your developers and business partners
Disadvantages:
-
Possible instability due to the smallest change in data that cause major changes in the decision tree structure
-
Sometimes require much more complex calculations compared to other existing algorithms
-
Decision trees are relatively more expensive and time-consuming in training
-
Are not suitable for solving regression problems or predicting continuous values
Support vector machines (SVM)
Advantages:
-
Work well even with unstructured and semi-structured data
-
Have less risk of overfitting
-
Work relatively well in scenarios with a clear margin of separation between classes
-
Much more effective in high-dimensional spaces
-
Very effective in scenarios where the amount of dimensions is higher than the number of samples
-
Relatively memory efficient compared to other algorithms
Disadvantages:
-
No probabilistic explanation for the classification
-
No standard for choosing the kernel function
-
Not suitable for massive sets of data
-
Do not perform well when the data has a big amount of noise and target classes are overlapping
-
Will underperform in scenarios when the number of features of each data point will exceed the number of training data samples
K-Nearest neighbors algorithm (KNN)
Advantages:
-
Zero time for training. KNN is often called lazy learner or instance-based learning. Because the algorithm doesn’t learn during the training period and does not derive any discriminative function from data, we can consider that it doesn’t have a training period. It has a storage of training datasets and learns only when making real-time predictions. This feature makes this algorithm faster than the other alternatives that require training
-
Seamless adding of the new data. Because the KNN algorithm doesn’t need training before actual prediction generation, you can add new data easily, and it will not impact the overall accuracy in any way
-
Ease of implementation. To make it work, you only need two parameters, the value of K and the distance function
Disadvantages:
-
It is not the best option for a large dataset, because the final cost of determining the distance between the new point and each of the existing points will be massive and will decrease the performance level of the algorithm dramatically
-
Not the best option for multiple dimensions. Once again, with a big number of dimensions KNN algorithm won’t work well, because of the need to calculate the distance in each dimension
-
Requires feature scaling. The feature scaling, standardization, and normalization are mandatory before applying the algorithm to any dataset. Without this move, there is a risk for KNN algorithm to make wrong predictions in the end
-
“K” in the algorithm must be determined in advance
-
The algorithm is very sensitive to the unbalanced datasets
-
Too sensitive to missing values, outliers, and noisy data. With the KNN algorithm, we can’t allow noise in the dataset. All missing values must be added and outliers removed manually to make the algorithm work properly
Conclusion
In the article, we highlighted the three most popular machine learning algorithms to solve a predictive maintenance challenge across various industries. As you see, there is no ultimate solution that will fit any situation like a glove. A proper algorithm must be chosen carefully and rigorously, based on your specific problem, available dataset, time and budget, and your business goals. While machine learning and AI used to predict machinery failure offers powerful techniques for predictive maintenance challenges, they are far from perfect and have their own limitations and disadvantages. In most cases, you need meaningful data that is properly collected and processed in the right way to build the ML solution for a hydraulic system.
The best option is to contact a team of experienced machine learning experts who know how to implement machine learning for predictive maintenance, evaluate your business situation, design a data collection pipeline, and develop a custom solution. At Intelliarts, we help organizations launch successful predictive maintenance machine learning projects that save costs, reduce downtime, and improve equipment reliability.
Follow our articles and get all the insights, as we continue to share our experience on advanced machine learning techniques, including automated data extraction from PDF, which can transform unstructured data into actionable insights, enhancing decision-making processes.
We at Intelliarts love to help companies to solve the challenges with data strategy design and implementation, so if you have any questions related to predictive maintenance machine learning algorithms in particular or other areas of machine learning — feel free to reach out.
FAQ
1. Can machine learning techniques be applied to different types of equipment?
Machine learning techniques could be applied to different types of machines, tools, and equipment which IoT sensors are connected to. Of course, sometimes, equipment is too old to implement predictive maintenance, so a manufacturer would need to update it first.
2. What types of data are needed for machine learning-based predictive maintenance?
To implement ML-based predictive maintenance, manufacturers will find useful any data that they can record with the help of IoT sensors. For example, companies can measure temperature, pressure, vibration, oil contamination, noise, water quality, chemical and gas emissions, flow, proximity, humidity, etc. This all depends on the manufacturing industry the company operates in and its needs. Also, for machine learning, four types of data are preferred: numerical, categorical, time series, and text data.
3. How can predictive maintenance with machine learning be implemented in your organization?
ML-powered predictive maintenance is usually implemented in a few steps. First, your organization has to review historical and real-time data available. Then, determine the critical assets and install IoT sensors on them. A good idea is to start with a pilot PdM project, which will include one or two assets only. After the project succeeds, move on and scale it.
See all questions

By
Yurii Laba
DS/ML Engineer
Structure

White paper
Turning Predictive Maintenance into a Success Story for Your Manufacturing Company
Get our PdM white paper






