In the highly digitalized world, the usage of information is key to business success. For a company to effectively handle both structured and unstructured data from various sources, it requires a set of tools and processes, or to put it simply, a data pipeline.
As a C-level executive or a software engineer, you may be particularly interested in the usage of different types of data pipelines architecture for your company’s benefit. This post allows you to delve into the concept of data pipelines and their architecture, explore key features these processing methods may have, what business value their usage has to offer and data pipeline examples.
Data pipeline vs. big data pipeline
Data pipeline and big data pipeline are two similar concepts, which are often used interchangeably, which is not exactly correct. Let’s delve into what is a data pipeline and big data pipeline, what is the difference between them and how both types of data pipeline works:
- Data pipeline refers to a set of processes and systems involved in moving and integrating data from various sources. This comprehensive system is created to collect, structure, and transmit data for the purpose of obtaining precise and useful insights, with diverse data pipeline use cases.
- Big data pipeline is the same data pipeline designed to handle much larger volumes of data and more complex data processing tasks. It often deals with data that is too voluminous, diverse, or fast-moving to be processed with traditional data processing tools. They may process data in batch, stream processing, or other methods. Data pipeline software is instrumental in managing these tasks efficiently.
Both data processing concepts involve steps of data collection, data transformation, and data storage. In the case of big data processing pipelines, the last step is obligatory data analysis, which is often done with the assistance of ML models. Regular data pipelines allow access to data immediately after its storage.
The most important difference between big data pipelines and regular pipelines is the flexibility to process massive amounts of data.
A data pipeline needs to be scalable to meet the organization’s big data needs. Without proper scalability, the system’s processing time may significantly increase, potentially taking days or even weeks to complete the task.
You may discover more about the role of data pipelines in an ML project from our other post.
Data pipeline components and building blocks
In this section, let’s deepen into how a data pipeline works and explore data pipeline architecture examples. Its architecture is designed to efficiently manage all data events, simplifying analysis, reporting, and usage. Such a digital system as a data pipeline encompasses the following six components and processes:

Data sources or origin
Origin is the initial data entry point, forming the backbone of the data collection pipeline. It may encompass a wide variety of data sources such as transaction processing applications, IoT devices, social media, APIs, public datasets, and storage systems.
Data destination
The destination is the endpoint of the data pipeline where data is transferred, and it is use-case specific. Data might be directed to power data visualization tools and analytics applications or stored in data lakes or other types of data storage, shaping data pipeline infrastructure.
Data storage
Data storage refers to systems where data is preserved at different stages as it moves through the pipeline. Examples include data lakes and lakehouses, data warehouses, databases, local storage vs cloud storage, and Hadoop Distributed File System (HDFS), forming the backbone of data pipeline structure. Data storage choices depend on various factors, for example, the volume of data, frequency, and volume of queries to a storage system, uses of data, etc. Investing in proper data warehouse development ensures that these storage solutions remain efficient, scalable, and secure.
Incorporate big data into your processes.
Harness the power of data, make informed decisions, and boost performance
Learn more
Data processing
Processing encompasses the series of operations involved in ingesting data from sources, forming the core of data engineering pipeline architecture. It also concerns data pipeline processes of storing, transforming, and delivering data to the specified location.
You can also explore our Data Engineering Consulting Services.
While processing is intertwined with dataflow, it focuses on the mechanisms used to facilitate this movement. Techniques of pipeline data processing may include data extraction from source systems, database replication, data streaming, etc.
Data workflow
Data workflow defines a sequence of processes or tasks and their dependence on each other in a data pipeline. Key concepts include job, upstream, and downstream. A job is a discrete work unit performing a specified task on data. Upstream refers to the data source entering the pipeline, whereas downstream refers to the output of the pipeline.
Data monitoring
The monitoring component aims to evaluate the functionality and efficiency of the data pipeline and its individual data pipeline stages. It checks the pipeline’s scalability with increasing data loads, maintains data accuracy and consistency throughout processing stages, and ensures data integrity.
Should you need a trusted partner for building a data pipeline or big data pipeline, don’t hesitate to reach out to ML engineers from Intelliarts AI.
Types of data pipeline architectures
Let’s review six common data pipeline examples to understand better what a data pipeline is.
ETL and ELT data pipelines
ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) data pipelines are two approaches for collecting, processing and storing data. As mechanisms of handling data, they belong to the processing component, as detailed previously. These types of data pipelines are foundational to an entire system for data handling. Here’s their concise overview:
- ETL data pipeline
In an ETL pipeline, the software first extracts data from different source systems, then applies transformations to make it suitable for analysis. Means of analysis may include aggregating data or resolving inconsistencies. Finally, the software loads data into a data warehouse or data mart.
This method is commonly used when there is a need to regulate the transformation process and when the data warehouse cannot handle the transformation itself.

- ELT data pipeline
The ELT pipeline retrieves data from source systems, transfers it to the data warehouse in its raw form, and then applies transformations to it.
This method utilizes the advanced computing abilities of contemporary data warehouses to transform data. It is commonly employed when the data for analysis should be left in an unprocessed state. When choosing a platform for this approach, an ETL tools comparison should include factors like connector coverage, transformation flexibility, and cost at scale.

The choice between ETL and ELT largely depends on the specific needs of a project or organization, including the volume and variety of data, the computational power of the data warehouse, the desired speed of data availability, and the need to store data in its raw form.
Batch and stream data pipelines
Batch and stream data pipelines represent two distinct approaches to data processing. They define the way in which data is accumulated and moved through the pipeline. Here’s a brief overview of these mechanisms:
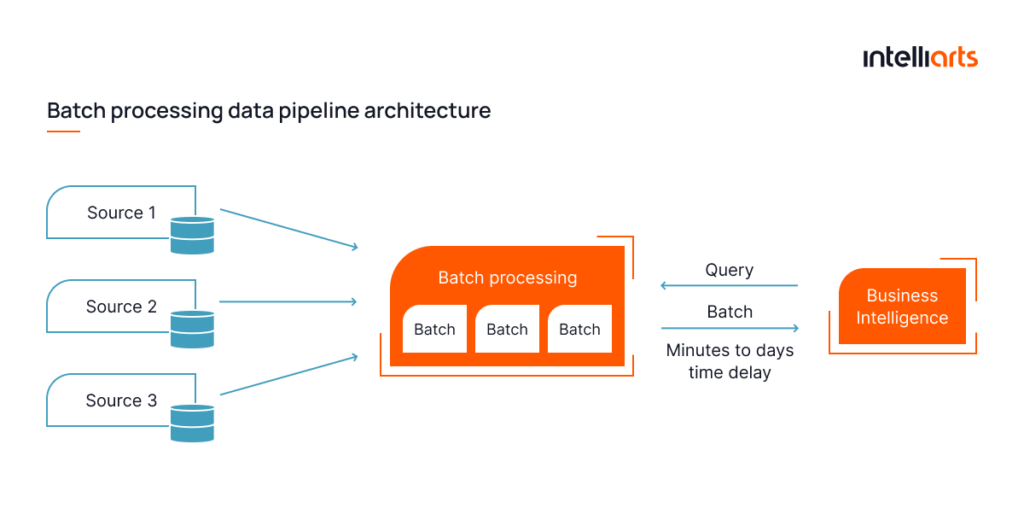
- Batch data pipeline
This type of data pipeline process data in large, discrete batches. It collects data over a certain time period or until a certain amount has been accumulated and then processes it all at once.
This method is suitable for non-time-sensitive operations and for cases when a business has to deal with massive volumes of data. Possible scenarios for using batch processing are daily or weekly reporting, data synchronization, or large-scale data transformation.
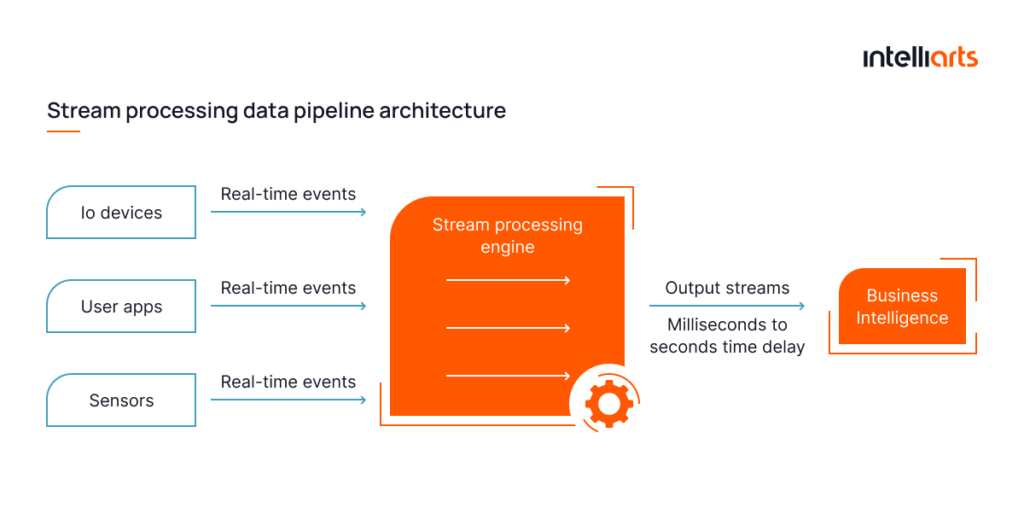
- Stream data pipeline
Stream processing pipelines handle data in real-time or near-real-time. It’s achieved by processing each data item individually as it arrives in the pipeline, which allows for continuous, instantaneous data processing.
This method is particularly suitable for real-time analytics, real-time decision-making, and event-driven applications. Possible scenarios for using stream processing are fraud detection, live monitoring, and real-time personalization systems.
Cloud and on-premise data pipelines
Cloud and on-premise data pipelines represent two types of infrastructure setups for handling data processing.
- Cloud data pipeline
Cloud data pipelines refer to the infrastructure that is hosted on the cloud by third-party service providers. This setup can provide various advantages such as scalability, reduced operational cost, flexibility, and accessibility from any location.
This method is particularly beneficial for smaller organizations or startups as it doesn’t require significant upfront infrastructure costs. Examples of cloud services include AWS Data Pipeline, Google Cloud Dataflow, and Azure Data Factory.
- On-premise data pipeline
On-premise data pipelines are set up within an organization’s own infrastructure. They typically offer more control over data and processing since the organization owns the servers and other related hardware.
This method can offer enhanced data security and privacy, which is particularly important for organizations dealing with sensitive data or operating under strict regulatory environments. However, it comes with higher upfront costs and the need for regular maintenance and upgrades, which the organization must handle itself.
It’s also worth mentioning that combinations of the listed above data handling and data processing mechanisms and infrastructure setups are possible. These are called hybrid pipelines. They may be as complex as the business require them to be. Most intricate systems can be easily designed to combine elements of ETL and ELT, batch and stream, and have both on-premise and cloud infrastructure.
You may also be interested to learn about ML-based data extraction in the insurance business.
Key features of big data pipelines
Now, let’s proceed with learning or refreshing the knowledge about eight main attributes that big data pipelines may have. Here we will also mention the data pipeline architecture best practices.
- Scalable cloud-based data pipeline architecture. It enables dynamic adjustment of computational resources based on data volume. Such architecture grants flexibility in handling varying data loads efficiently, without compromising speed or performance. It is essential for managing big data in the cloud.
- Fault-tolerant architecture. It ensures continuous operation of the data pipeline even in the event of component failure. It automatically recovers or switches to backup systems, preventing data loss and maintaining the pipeline’s reliability and consistency.
- Transforming high volumes of data. This involves the efficient processing of large data sets. Big data pipelines transform, clean, and normalize data at scale, making it suitable for further analysis and aiding in data-driven decision-making.
- Real-time analytics and data processing. This allows immediate data processing and analysis as soon as it enters the pipeline. This feature enables businesses to gain instant insights from their data, supporting real-time decision-making.
- Self-service management. It empowers users to manage their data workflows with minimal technical support. It allows non-technical users to access, prepare, and analyze data, democratizing data use this way.
- Streamlined data pipeline development. This grounds on DataOps — a methodology that combines diverse technologies and processes in order to reduce development and delivery times. Streamlining pipeline development and deployment makes it easier to modify or scale pipelines as well as accommodate new data sources.
- Exactly-once processing. This means that dataflow commits every record to storage exactly once, eliminating duplicates. Exactly-once processing is crucial for maintaining data integrity and accuracy and for ensuring consistent analytical outcomes.
- Automated data quality checks. They automatically deliver and address data anomalies, inconsistencies, or missing values. This way, it preserves the integrity of the dataset, ensuring the accuracy and reliability of data throughout the pipeline.
It’s advised to create data pipelines with these best practices in mind. This way, you’ll ensure the high performance of your data processing infrastructure and minimize the risks associated with its potential malfunctioning.
Should you require assistance with building a data pipeline or big data pipeline architecture, don’t hesitate to reach out to our team of well-seasoned AI and ML engineers.
Business use cases of data pipelines
Here are some of the ways in which data pipelines can help businesses get a competitive edge, enhance their operational performance, and meet industry standards:
-
Business Intelligence
Data pipelines provide a holistic view of business operations. This critical insight enables leaders to spot trends, make informed strategic decisions, and optimize overall performance.
-
Predictive Analytics
Data pipelines can power predictive analytics tools to forecast trends, customer behaviors, and market movements. This foresight helps executives to take proactive measures.
-
Fraud Detection
With data pipelines, businesses can rapidly process and analyze vast transactional data making it possible to detect fraudulent activities in real-time. This can protect the company’s assets and maintain customer trust.
-
Real-time Reporting
Data pipelines can stream real-time data, providing up-to-the-minute information. It helps to maintain the pulse of operations, track performance metrics instantly, and respond to issues as they arise.
-
Customer Segmentation
Data pipelines aggregate data from various customer touchpoints, enabling advanced segmentation. This helps in personalizing marketing strategies which leads to increased customer loyalty and improved sales performance.
-
Supply Chain Optimization
Data pipelines can uncover hidden inefficiencies and bottlenecks in the supply chain. Such insights facilitate more effective IoT supply chain optimization, and resource allocation, improve logistics and inventory management.
-
Risk Management
Data pipeline helps to quickly process diverse data sets to identify potential threats and vulnerabilities. These insights help businesses anticipate risks, enforce preventative measures, and ensure regulatory compliance.
6 incredible advantages of using data pipelines in business
Making use of data pipelines for small to large-scale businesses is totally recommended. Here are some of the advantages of data pipeline:

Need help with applying data pipelines to your business tools?
In one of our past projects, the Intelliarts team of engineers built an end-to-end big data pipeline for a US-based data-driven market research company. We developed a solution that enables the customer to manage data from the moment of data collection to delivery.
Here at Intelliarts, we specialize in data pipeline development that is tailored to your business needs. Our team of experienced professionals can design and implement efficient data pipelines, transforming your data into actionable insights. Our efforts in this niche were recognized by TechReviewer.co which included Intelliarts in their list of the Top Big Data Analytics Companies in 2023.
Building and managing data pipelines
There’s nothing more helpful for grasping something new than concrete tips and advice. Let’s review some of the best insights on building and managing data pipelines that practicing data engineers at Intelliarts can share:
- Design with scalability and modularity in mind
Ensure your data pipeline can handle both current and projected data loads. Use distributed data processing frameworks (e.g., Apache Spark, Apache Kafka). Build your pipeline in modular chunks, allowing for easy testing, debugging, and replacement of individual components.
- Ensure data quality and integrity
Implement data validation checks at every stage of the pipeline. For instance, ensure that data types, ranges, and formats match the expected schema. Actively monitor your pipeline for failures, delays, or anomalies. Tools like Apache Airflow or Apache NiFi provide monitoring capabilities out-of-the-box.
- Maintain idem potency and retries
Design processes so that they can be safely retried without creating duplicate or incorrect results. Incorporate automated retry mechanisms, especially when interfacing with external services that might occasionally fail.
- Document everything
Clearly document the design, architecture, and purpose of each component of your pipeline. Ensure that configuration details, schema definitions, and assumptions about the data are documented. Metadata management tools can also help keep track of lineage, schemas, and transformations.
Surely, there is much more to add about data pipeline management. But the detailed above can help you break the barrier to entry.
Final take
As can be concluded, data pipelines heavily impact how businesses handle the data in their digital environment. The detailed six types of data pipeline architectures and their features can be combined to create a perfect-fit solution to a company’s needs. The resulting system should be able to flawlessly handle unstructured data of varying types, be scalable, and reliable.
Building data pipelines for your business is a task that requires high expertise and proficiency in ML. As a C-level executive, you may consider contacting a trusted ML development company. This way, you will get professional help with developing and integrating data pipelines into your infrastructure, which may result in numerous operational advantages for your company.
FAQ
1. When do you need a data pipeline?
Data pipelines address the need to process and move data from one system to another. Usually, the data is used to perform analytics, make informed decisions, serve machine learning models., etc. Data pipelines are obligatory when dealing with large-scale data that needs to be transformed, cleaned, or combined.
2. Is it possible to automate big data pipelines in business?
Big data pipelines are meant to be automated. This way, they can help to handle vast amounts of data efficiently, ensuring data is regularly updated and available for use. Technologies like Apache Airflow, AWS Glue, and Google Cloud Dataflow offer solutions for automating these pipelines.
3. What are the requirements for the big data pipeline?
The requirements for a big data pipeline include a clear understanding of the data sources, the processing and transformation needs, the data destination, and the data handling capacity. Also, robust infrastructure, whether it’s cloud or on-premises, effective error handling mechanisms, and strict data security and privacy standards in place are necessary.