

Cultivating a prospect from lead generation to the actual sale is a complicated and usually time-consuming process. How often does it happen to an insurance agency when the leads show a momentary interest in the services only to evaporate when the insurance agents call them with a specific offer?
An insurance marketing department can generate hundreds of leads before a sales team discovers that only a small percentage of these are convertible. Your insurance company might consider using a predictive AI lead scoring software to spend less time on low-quality leads and avoid wasting business resources.
By allowing you to prioritize leads, predictive lead scoring automates your insurance sales process and increases the accuracy of results. Below we describe the benefits of machine learning-based lead scoring and our lead scoring case study where you can see how we’ve built a predictive solution for our insurance partner .

Does lead scoring matter?
What is predictive lead scoring? It may be easy to understand the concept of lead scoring in insurance, but a bit tricky to put it into practice. Simply put,
Lead scoring means ranking insurance leads based on their likelihood of buying an insurance policy.
This final “score” is calculated from multiple (and the most diverse) factors, such as demographics, behaviors, and quotes, and then compared and contrasted to the actions taken by previously converted leads.

Once the score is assigned to a lead, insurance agents know to whom to devote more time and attention. The sales team doesn’t waste time on unqualified leads anymore, so the insurance company should expect an increase in sales productivity and better ROI.
In contrast, poor lead scoring risks missed sales goals and demoralized insurance agents. The latter could experience burnout and high turnover because of wasting their energy on less promising leads, which eventually don’t bring any conversion. This also makes companies pay extra for training and agent staff expansion.
Why does traditional lead scoring fail you?
Traditional lead scoring refers to the process where the sales team determines the lead’s quality based on a variety of factors and then assigns a score to this lead. In insurance, this is usually done by using some formula or a marketing automation tool, which can track the leads’ behavior attributes to get a fuller picture of the prospect’s desire to make a purchase.
So what’s wrong with this strategy? Traditional lead scoring in insurance is significantly limited, focusing primarily on the top of the funnel. It doesn’t take into account the complexity of today’s customer journey, which has become as diversified and non-linear as ever before.
Below is one of many other examples of what a customer journey in insurance could look like. But this might change a lot, depending on the insurance sector the company operates (car insurance, property insurance, etc.), its preferred sales and marketing tactics, technology use, and so on.
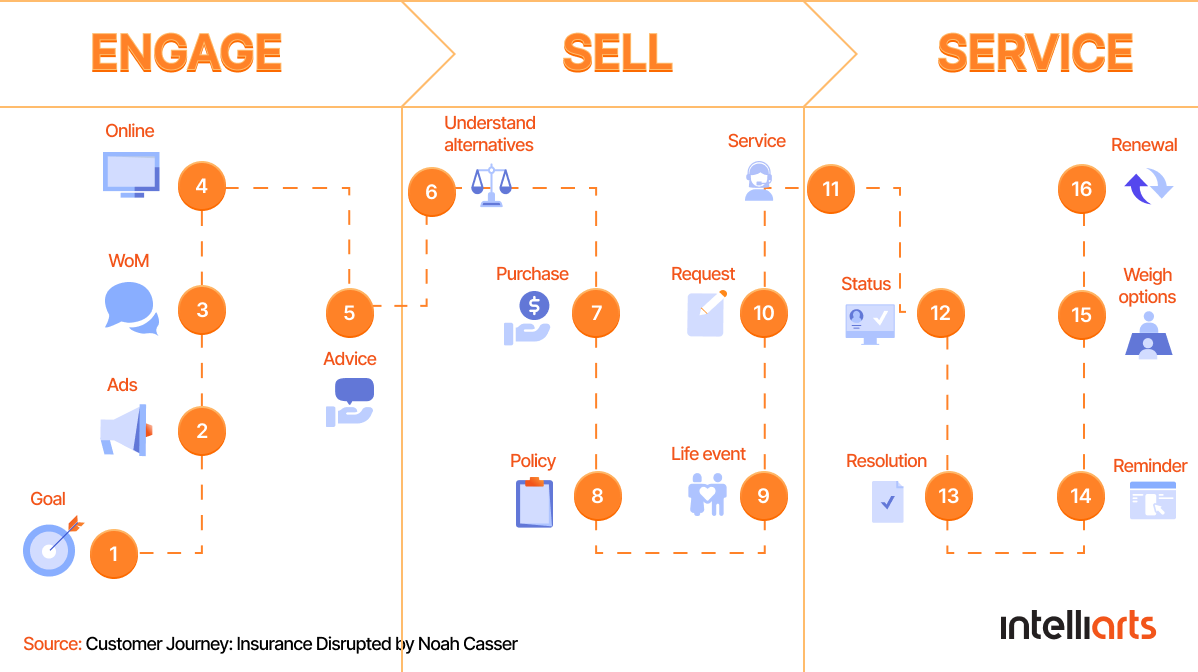
So if we briefly sum up why a traditional lead scoring model is failing your insurance business, we can mention that it’s:
-
Restricted: How many criteria could you include in traditional lead scoring? Three? Five? Ten? Regardless of the number, it’s usually not enough. And in this case, your business cannot consider complex relationships between these factors, causation, and correlation. As a result, you get an inaccurate lead score, which means lost opportunities for the insurer or, vice versa, wasted time for non-qualified leads again.
-
Labor-intensive and static: Okay, you try to diversify the criteria as much as possible, putting lots of time and effort into building an ideal traditional lead scoring system. But what are the guarantees that this system stays the same accurate and relevant in, let’s say, three months? New lead sources, metrics, and mediums could be added to an insurance customer journey at any moment. And if the insurer continues to commit to the lead scoring system that couldn’t dynamically adjust to these changes, it should expect inaccuracy in its scoring results.
-
Based on assumptions: In traditional lead scoring, the factors are usually selected based on guesses and assumptions. The management relies on the information from previously converted leads. But the analysis needs to be more comprehensive so the lead scoring was data-driven.


How to strengthen your insurance lead scoring system?
Easily! Use predictive lead scoring machine learning. The idea behind predictive lead scoring is to apply machine learning (ML) to calculate the lead score with the help of technology. In this scenario, an insurer benefits from:
-
Using a more data-driven approach, with real-time data input analyzed through ML algorithms
-
Less guesswork and more accuracy instead, as predictive lead scoring results in a more detailed and complete lead profile
-
Uniqueness — since each insurance company has its unique criteria to take into account in lead scoring, model scoring in machine learning allows you to rely on them
-
A high variety of scoring factors, which can help to discern previously unknown patterns in lead quality
-
Getting more objective in decision-making since no humans are involved in lead scoring
-
Higher speed and automation
-
Improved flexibility — although it’s hardly possible to build an ideal scoring system, predictive lead scoring allows you to refine and retrain the model whenever new data appears.

Challenges and considerations of predictive lead scoring in insurance
When weighing over the implementation of predictive lead scoring, make sure your company considers potential challenges as well:
- Data-intensive models: For better accuracy, you need lots of quality data to feed your machine learning algorithms with. Sometimes, insurance companies don’t even realize they’re sitting on massive data, wasting its big opportunities.
- Time and money resources: Some might say that predictive lead scoring requires heavy investments, which makes it less accessible to small- and medium-sized businesses. The truth is cloud solutions and third-party partnerships provide companies with more opportunities to implement predictive models. Moreover, insurers don’t have to dive into big ML projects from the start. A better strategy is to scale predictive lead scoring step by step as soon as the project brings its first results.
- Sales team not on board: To make lead scoring using machine learning work for your company, you as an insurer need to convince the sales team of its importance and helpfulness. A good starting point is to join your efforts with ML experts and organize workshops on how to use predictive lead scoring, explaining its best practices and nuances of how ML works.
To describe the process of building an ML-based lead scoring solution, we’ll tell how the Intelliarts data science consulting team developed one for a midsize insurance company.
Lead scoring case study
Business challenge
Our customer is a midsize insurance company working in property insurance. The company has a traditional workflow to process leads acquired from multiple sources, including telemarketing, partnerships, website, and others. Then, it follows up leads by cold calling, offering insurance policies.
However, a large variety of leads is hard to handle and requires the exploitation of our customer’s resources. The insurer spends extra on hiring and training agents and their wages. So, the customer’s decision to contact Intelliarts was connected to their goal of optimizing resources and building an effective ML-based lead scoring system.
Additionally, the insurance company approached us with the request to increase lead scoring efficiency using machine learning. The customer has noticed that not all leads that they contact are of the same quality. For instance, an agent could spend on cold calls three hours and sell only one policy. And the other day, the same agent could sell two or three policies during a 30-minute call.
Solution
ML-powered lead scoring solution
Having consulted the customer, we decided to build a predictive lead scoring model in machine learning that could forecast the probability of how likely the lead would buy a policy. With this system in place, insurance agents could call leads with high scores first and leave those leads with low scores for later or skip them entirely in case of lacking resources.

To build this solution, we started with a data collection process. The information we collected with the help of the insurance company could be grouped as:
-
Source data: from where and how leads come to the insurer (partners, lead capture tools, company websites, and so on)
-
Behavior data: how leads interact with the customer (calls, website visitors, email clicks)
-
Quote data: historical estimations of how much a policy would cost
-
Demographic data: all sorts of information about the age of leads, their addresses, and FICO credit score
-
Property data: size calculated in square footage, the year when a property was built, coverage, and potentially dangerous factors
-
Contact data: how they reached out to the lead before
In modeling, our data engineers decided to use gradient boosting techniques with this data because of three reasons: the data was tabular; it had lots of categorical features; and the target was binary (sold vs. not sold).
At this stage, we faced lots of related problems, among which were missing data and different historical factors. Since leads don’t always share their complete information, we had some gaps in the data. The challenges caused by historical changes in the company involved modifications in business processes, partners who stopped working with the customer, and the addition of new policies.
To solve these data problems, Intelliarts engineers built a Python module that contained a lot of different blocks, including:
-
Extracting useful features from text and time data
-
Grouping the same and similar records to prevent model uncertainty
-
Cleaning data and replacing the missing values
-
Cleaning anomalies and outliers in data to exclude some impossible values, e.g. negative age
-
Grouping some categories and providing encoding for them to be able to work with new partners or in the new state in the future
-
Intelligent replacement of the missing values
With this approach, our data scientists didn’t only manage to address the data challenges we met. We also discovered multiple insights about the insurer’s data that helped us improve the data collection logic and strengthen the ML lead scoring solution further.
A few months later, we also started to track and use historical measurements. Every month, the model analyzes which of the states, partners, lead sources, etc. has performed better. Based on this, the lead score gets updated. For example,
-
There are leads coming from a landing page and emails.
-
Out of the ML model results, we notice that the landing page converted three times more leads than email the previous month.
-
The model takes into consideration that the landing page converted more leads the previous month and improves the prediction score for the next month.
-
The same approach works at the level of states, partners, etc.
Moreover, the customer received significant business gains a few months after implementing the lead-scoring solution. So we decided to use the same approach to replicate the results by building one more predictive model for prospects. After all, the scoring solution became more complex as the customer ranked the potential buyers in two phases to improve the quality of leads and prospects.
ML-based efficiency solution
The second solution we built purposed at improving lead efficiency. We used the same features as before but changed the target this time. Now our data scientists tried to predict the score continuous number, which can be described as a traditional regression task in machine learning.
The score we calculated was the number of sold policies divided by the call time that the insurance agents spent on this particular lead.

The main issue we faced during the modeling stage was lots of messy data related to call duration. For example, there was the data received from answering machines, the problem of poor aggregation, and others. All this confused the model and caused inaccurate prediction results.
For this challenge, we used the same Python module for data cleaning.
But it was difficult to design correct training, validation, and testing datasets for the lead efficiency model.
Here is how we solved it:
-
As said, we considered efficiency as the number of policies bought by a single lead divided by the call time spent on this lead. Importantly, there could be several calls and insurance agents who worked with this lead.
-
Since there were lots of leads, the success rate wasn’t really big. Thus, we faced the problem of imbalanced data and the situation when most of our scores equaled zeros.
-
For this very reason, we couldn’t include all leads to avoid lots of zeros, i.e., leads for whom agents spent some time but didn’t sell any policies. To solve this issue, we used only converted leads in training data.
-
The next issue that arose was concerned with testing and validation. If we used only converted leads, we wouldn’t get a full picture. In the reality, we cannot know whether leads are sold at the time when the model is still running a prediction for lead efficiency.
-
We also couldn’t leave the same distribution as in the original data because we risked getting a lot of mispredictions. The model predicts a score, but leads would get zero because no one had bought a policy.
-
To solve this problem, we decided to use the previous lead scoring model we had built to run a test only on those leads that had high scores predicted by the ML model. This helped us reduce the number of non-sold leads and, thus, achieve the best results in terms of business metrics.
Business value
We built a workable ML-based scoring model with over 90% accuracy and good results in production. After a few months, the scoring prediction model cut off approximately 6% of leads, which helped the insurer increase its profit by 1.5%. In the most successful months, the customer noticed a 2.5% increase in profit.
The graph below shows how the expected profit changes depending on the profit threshold:

With this scoring model, the insurance company can group leads by the probability of being sold. Now the group with an 80% probability and more has an expected conversion rate 3.5 times bigger than the average conversion.
In contrast, the bottom group with 20% and less probability predicted by the model has 5 times lower than on average. As a result, the customer doesn’t have to waste time on 20% of all leads which wouldn’t bring any efficiency to the insurer.
Overall, the lead scoring system removes any guesswork from lead scoring and prevents wasting business resources.

Moreover, the machine learning lead scoring efficiency model we built helps the customer with predicting lead quality, so the company gets more quality leads from the start. Lead quality does matter to insurance companies (as well as in any other industry) because it’s a key indicator of future sales success.
If the insurer attracts low-quality leads (even if there are many of them), the conversion rate would be low. And this doesn’t bring any monetary value to the company.
Together, the models save agents’ time, as they don’t call leads with potentially low conversion rates, help the company optimize the sales workflow and improve performance.
Last but not least, we didn’t only build the two ML models. The Intelliarts data engineers also deployed the trained models using Amazon SageMaker. We integrated the two solutions into the customer’s system to establish connectivity and help the insurtech company avoid any system integration challenges that could arise. As it’s a full-cycle ML project, we continue to assist the company with solutions maintenance and are ready to fine-tune or retrain any model if the data changes.
Intelliarts as your predictive lead scoring partner
As you see, predictive lead scoring is a large part of Intelliarts’ expertise. We have an experienced team of data scientists and machine learning engineers with solid expertise of ML in the insurance sector. From NLP to computer vision to predictive analytics, we build full-cycle ML solutions tailored to your specific needs.
Aside from the predictive lead scoring model, Intelliarts has also recently built an ML-powered solution to increase lead quality and agent efficiency. Our data scientists have performed data science research purposed to improve cold calling success rates in insurance.
Wrap up
According to Gartner, 70% of leads get lost because of poor follow-up. And every lost lead equals a missed opportunity in insurance sales. Still, an insurance company can attract hundreds of leads coming from different sources daily. How should you prioritize them?
The best idea is to incorporate a lead scoring system, which will prompt your agents whom to call first to get higher conversions and avoid wasting company resources. Even better, an intelligent machine learning lead scoring system like the one we built for the insurtech customer helps insurers adjust lead scoring based on real-time data and results. Let alone, if you decide to empower these lead scoring solutions with better lead quality achieved by implementing an ML-based lead efficiency system.
Read also how integrating an automated data extraction solution can greatly enhance the efficiency of sorting and processing large volumes of information, leading to more informed business strategies.

Are you also tired of wasting time and money on unsuccessful cold calls or want to prevent customer churn in the insurance business? Reach out to our expert Intelliarts team to implement predictive lead scoring and bring your sales effort in insurance to a new level.
FAQ
1. What kind of data do I need to implement predictive lead scoring?
Data types typically include lead source information, behavioral data (e.g., website interactions), demographic information, and any historical interactions with your company, such as calls or email responses. But if don’t have enough quality data, don’t worry — our data scientists can come up with a solution, such as synthetic data.
2. When can my insurance company expect first results from predictive lead scoring?
Results depend a lot on the quality and quantity of data, but many companies see measurable improvements within a few months of implementation.
3. Does predictive lead scoring require a large investment?
While there may be some upfront costs associated with implementing predictive lead scoring, you can significantly reduce expenses by using cloud solutions and partnering with third-party providers. Moreover, we can start from a PoC to demonstrate value and optimize costs, allowing you to see tangible results before committing to a full-scale implementation.









