

Real-time data has become essential for modern analytics and machine learning. In 2024, the global real-time analytics market reached $890.2 million, and it is projected to grow at a CAGR of 25.1% in the coming years. This growth highlights the rising importance of systems that can manage continuous, time-stamped information. A time series database (TSDB) technology supports this need by storing and organizing temporal data for forecasting, monitoring, and ML-driven insights.
In this post, you’ll find out what TSDB is and what its key characteristics are compared to traditional databases. Besides, you’ll see the connection of TSDB with ML applications and find out how to choose the best database for time series data in your project.
What is a time series analysis database?
A time series analysis database is a specialized data system designed to handle information that arrives as continuous, time-stamped sequences.
Within the machine learning ecosystem, a time series analysis database serves as the foundation for models that rely on temporal context. These include models used for:
- Forecasting. Algorithms that predict future values based on historical patterns.
- Anomaly detection. Systems that identify sudden or unusual deviations from normal behaviour.
- Predictive maintenance. Solutions that estimate equipment failures in advance based on sensor trends.
- Model performance monitoring. Solutions that track drift or degradation in an AI system through time-based metrics.
You can see that in each case, the models rely on long, continuous sequences of historical data to understand patterns and produce accurate predictions. A TSDB provides the clean, granular, and consistently structured data required by the pipelines that power these ML-driven systems.
Explore time series machine learning in greater detail in another blog post by Intelliarts.
Definition of time series data
Time series data is information collected as data points indexed in time order, with each measurement reflecting the state of a system at a specific moment.
This structure allows analysts and ML models to understand how behaviors, conditions, or signals change rather than viewing data as isolated snapshots.
Because time series captures continuous evolution, it helps reveal long-term trends, short-lived spikes, seasonality, cyclical patterns, or unexpected anomalies that would otherwise remain hidden. This temporal dimension is why it is fundamental to forecasting, anomaly detection, predictive maintenance, and real-time operational analytics.
Typical examples of time series data include:
- Sensor readings from IoT devices
- Stock or crypto price movements
- Server and application performance metrics
- Energy consumption measurements
- Environmental data such as temperature, humidity, or air quality
- Network traffic and bandwidth usage
- Smart meter readings
- Manufacturing machine outputs
- Financial trading volumes
- User activity or engagement metrics in digital products
Below is a sample time series dataset from a single environmental IoT sensor that monitors indoor air quality and ambient conditions in real time. Each timestamp shows the full state of the device, demonstrating how multi-metric time series data is captured and used for analytics, monitoring, and ML forecasting.
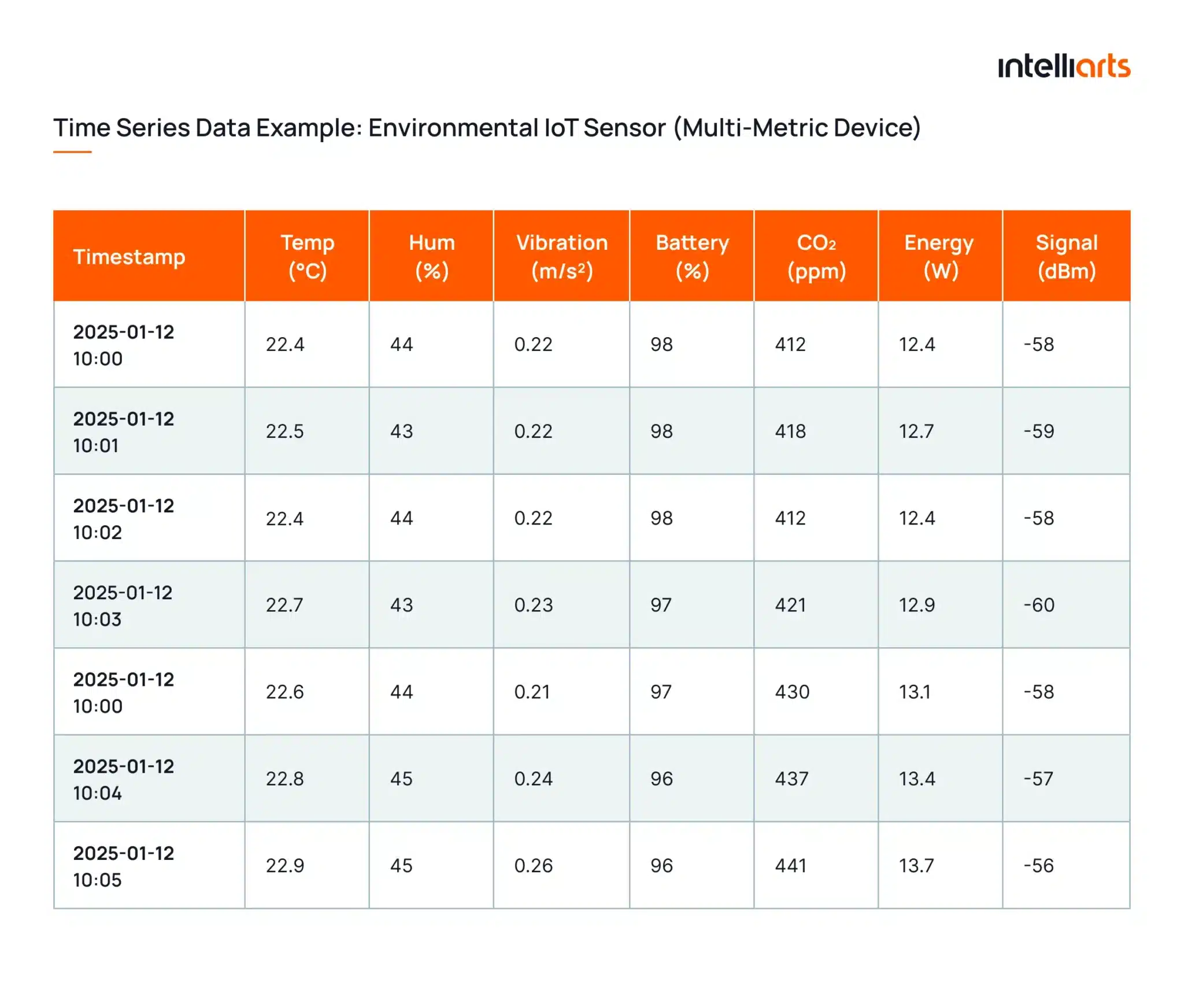
See more time series analysis examples in our corresponding blog post.
Key characteristics of a time series analysis database
As we already mentioned, a time series analysis database is a specialized system built to manage data that arrives continuously and is indexed by time. Its internal architecture focuses on how temporal information is stored, compressed, and organized at scale. Here are characteristics that indicate how the TSDB design is suited exactly to the unique demands of temporal data:
- A write-optimized storage engine built for continuous append-only workloads
- Time-oriented indexing structures that organize data by intervals, buckets or shards
- Compression algorithms tailored for sequential numeric data
- Columnar storage layouts that reduce I/O and accelerate time-based scans
- Native support for retention policies at the storage level (TTL, tiering, compaction)
- Efficient memory and caching strategies for recent, high-resolution data
These characteristics allow a TSDB to capture and structure temporal data in a way that supports analytics, monitoring, and machine learning workflows.
When we work with long-running telemetry or sensor data, having good time series database changes everything. It keeps the data clean, fast to access, and easy to analyze, so our ML models can focus on real patterns instead of constant fixing. — Marta Vikhrak, ML Engineer at Intelliarts.
Core purpose of TSDB
The purpose of a TSDB can be defined as providing a dedicated system for managing data that evolves over time.
TSDB captures continuous measurements and structures them as time-indexed sequences. Those sequences are available for further analysis, monitoring, and machine-learning workflows that depend on temporal patterns.
Putting it all into context, here are the responsibilities that TSDBs cover in operational systems, analytics pipelines, and ML environments:
- Serving complete chronological datasets for trend, seasonality, and pattern analysis
- Delivering precise time-based aggregations needed for dashboards, SLOs, and KPIs
- Feeding ML pipelines with clean sequences for lag features, rolling windows, and temporal context
- Supporting incident response and monitoring with fast access to the latest measurements
- Maintaining historical continuity so that long-term modeling and regression analysis remain reliable
- Providing accurate time alignment across metrics, devices, or systems for correlation or forecasting
These responsibilities describe how a TSDB behaves in real workloads. Since the importance of data analytics, decision-making, and ML is huge, TSDB can deliver a lot of business value by supporting these systems.
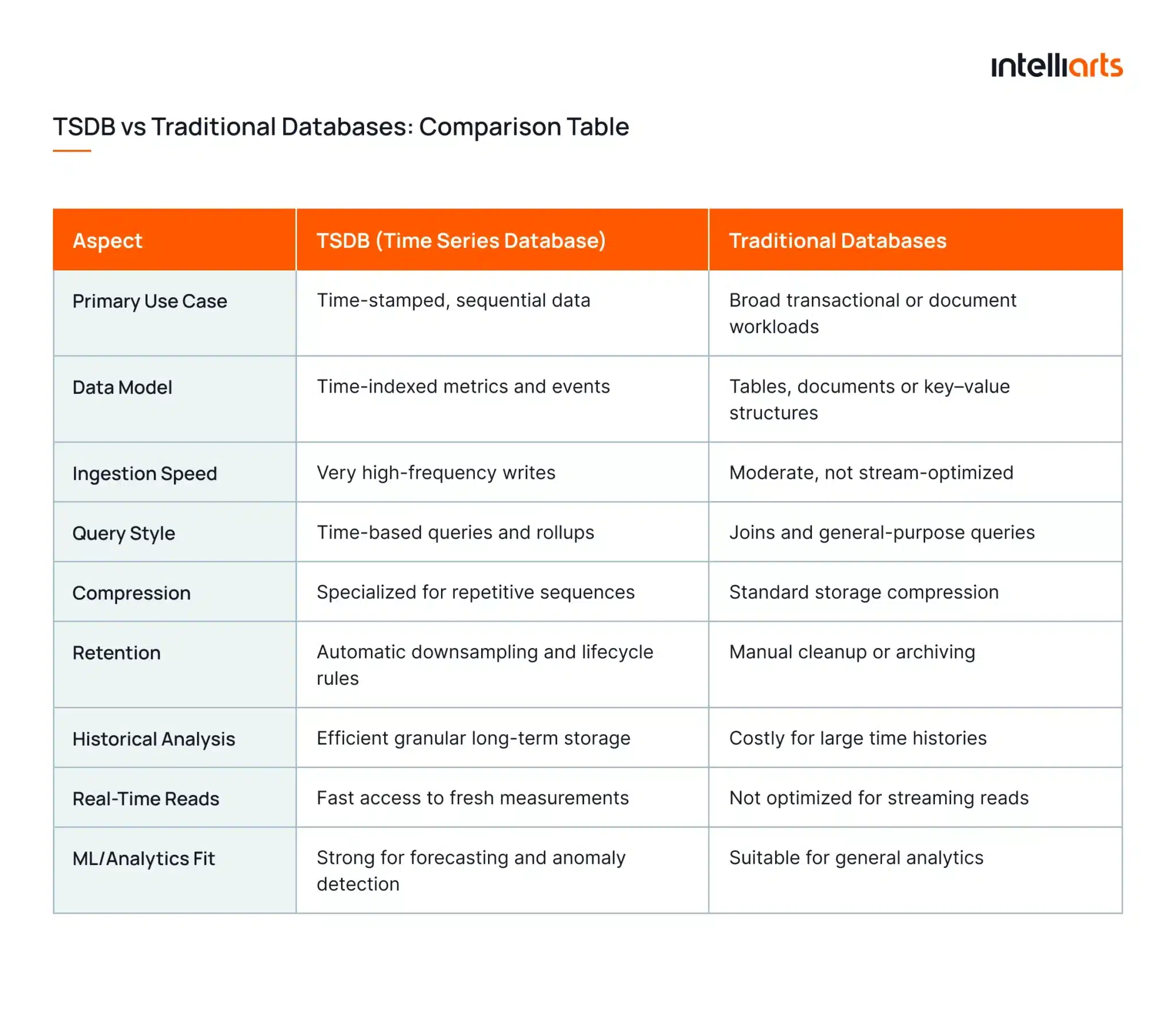
Contrast of TSDB with traditional databases
A time series analysis database is designed for continuous, time-indexed data, while traditional databases support broader transactional or document-focused workloads. To illustrate the differences clearly, the table below highlights how each system handles ingestion, storage, querying, and analytics needs.
Now that we know what time series data and time series analysis database are, let’s proceed to connecting them to ML applications and workflow.
Why time series databases matter for Machine Learning?
TSDB is of particular usefulness for ML systems. That’s because, based on the Garbage-in-Garbage-Out (GIGO) rule, ML systems in lots of applications require extensive data, which, ideally, has time stamps. Here are all the ways in which TSDB supports ML:
#1 Predictive maintenance for industrial equipment
What ML model does: Detects early signs of equipment failure using vibration, temperature, and pressure data. Needed to predict failures in turbines, pumps, industrial robots, or HVAC units.
How a TSDB supports it:
- Ingests high-frequency sensor readings
- Aligns multi-sensor time series
- Maintains long-term histories needed for failure-pattern discovery
Why it outperforms traditional systems:
- Traditional DBs cannot ingest thousands of metrics per second reliably
- TSDBs are engineered for dense, high-frequency telemetry
Real-life example:

An EV charging provider engaged Intelliarts to prepare the foundation for a future predictive maintenance system. The team analyzed large volumes of historical charger logs, identified abnormal behavior, cleaned inconsistencies, and converted raw telemetry into structured, machine learning ready data. This helped the customer understand which patterns typically lead to charger downtime.
These preparations created the data quality and organization needed for the company to later introduce an ML-powered maintenance workflow. A TSDB could then support real-time monitoring, continuous data ingestion, and timely model updates.
Explore the predictive maintenance for EV chargers success story.
#2 Anomaly detection in server and application metrics
What ML model does: Identifies unusual spikes or drops in latency, traffic, CPU usage or error rates. It’s used to prevent outages and detect abnormal system behavior.
How a TSDB supports it:
- Supplies clean rolling windows for training
- Delivers real-time measurements with low-latency reads
- Maintains data integrity during high-load events
Why it outperforms traditional systems:
- Relational DBs become bottlenecks under rapid ingestion
- TSDBs sustain high write throughput and fast streaming queries
#3 Demand forecasting in retail or logistics
What ML model does: Predicts product demand, inventory, and turnover using historical sales data, seasonality, and external signals.
How a TSDB supports it:
- Handles multiple temporal frequencies (daily, hourly, weekly)
- Supports cross-metric correlations (inventory, visits, promotions)
- Enables quick backtesting on long historical windows
Why it outperforms traditional systems:
- General-purpose databases slow down during repeated historical scans
- TSDB indexing makes sliding windows and rolling forecasts extremely fast
Real-life example:
A global electronics manufacturer faced challenges with stock availability and procurement planning. Demand patterns were inconsistent across hundreds of products. Intelliarts applied time series analysis to historical sales, pricing data, and product design-cycle behavior, uncovering clear seasonality and long-term demand signals.
The Intelliarts team built accurate forecasting models and integrated the results into the company’s dashboards. Procurement decisions became more precise, stockouts decreased, and marketing teams gained reliable insights for planning campaigns.
Read the machine learning in demand forecasting success story.
#4 Financial market forecasting and risk modeling
What ML model does: Forecasts short- and long-term market behavior using multivariate time series. It’s used in the finance domain to model price movement, volatility, and liquidity.
How a TSDB supports it:
- Handles large volumes of tick-level or millisecond data
- Provides tightly aligned sequences across instruments
- Enables fast correlation and cross-instrument analysis
Why it outperforms traditional systems:
- Relational systems choke on high-frequency financial data
- TSDBs are tailor-made for dense, fast-moving temporal streams
#5 Real-time user behavior modeling
What ML model does: Analyzes user interactions over time to detect patterns that signal churn, interest shifts, or fraudulent behavior.
How a TSDB supports it:
- Reads recent interactions in milliseconds
- Preserves chronological consistency across events
- Supports rapid feature computation (session windows, recency, frequency)
Why it outperforms traditional systems:
- Event tables grow too quickly and slow down SQL queries
- TSDBs compress and index these sequences efficiently
Core features of a time series database
Now you have an in-depth understanding of TSDB and know how it’s applied in ML. Let’s continue by delving into the core features of time series database architecture to see what capabilities exactly make TSDB as useful as shown above. It also includes an input and output examples.

#1 High write throughput and compression
What it is: A capability within a time series database that ingests continuous, high-volume measurements while minimizing storage overhead. It uses a write-optimized engine and compression tuned for sequential numeric patterns.
What it does:
- Accepts constant append-only writes from sensors, agents or telemetry pipelines.
- Batches measurements into time-ordered blocks.
- Applies temporal compression (delta, XOR, RLE) to minimize storage.
- Writes compressed blocks into sequential, low-latency storage segments.
Input:
- Time-stamped measurements
- Sensor data, logs, metrics
Output:
- Compressed, query-ready series
- Storage-efficient historical blocks
#2 Efficient time-based querying and downsampling
What it is: A capability in a database for time series data that enables fast retrieval of time-indexed records across selected ranges. It also provides mechanisms to downsample dense historical series.
What it does:
- Uses time-based indexing to locate relevant segments instantly.
- Executes interval-based aggregations (avg, sum, min, max).
- Produces downsampled views via bucketed rollups.
- Scans compressed structures to reduce latency and I/O.
Input:
- Time range parameters
- Query filters and aggregation intervals
Output:
- Fast aggregated results
- Lower-resolution series for dashboards and ML
Any time we see a client switching from scattered logs to a proper TSDB, the difference is huge. They see trends clearly, catch anomalies earlier, and build predictive models without spending weeks just cleaning or stitching the data together. — Volodymyr Mudryi, a data scientist and machine learning engineer at Intelliarts.
#3 Data retention and rollups
What it is: A capability of a database for time series analysis that manages the complete lifecycle of stored measurements through retention rules, archives and automated rollups for long-term efficiency.
What it does:
- Removes or archives raw data after defined retention periods.
- Runs scheduled rollups to summarize granular data.
- Moves historical data into lower-cost storage layers.
- Maintains consistency between raw, rolled-up and archived datasets.
Input:
- Retention and compaction policies
- High- and low-resolution time-series data
Output:
- Cost-optimized long-term histories
- Summarized datasets for trend analysis
Learn additionally about data preprocessing in machine learning in another of our blog posts.
#4 Built-in analytics functions
What it is: A capability in a TSDB that performs native analytical operations such as aggregations, correlations, and lightweight forecasting, directly on stored temporal sequences. No external systems required.
What it does:
- Executes statistical functions across time windows.
- Computes correlations and rate-of-change indicators.
- Generates forecasts using built-in temporal models.
- Returns pre-aggregated outputs without exporting data.
Input:
- Stored time-series metrics
- Analytical expressions, queries, or function calls
Output:
- Trends, correlations, anomaly indicators
- Forecast-ready signals for BI or ML pipelines
#5 Integration with ML frameworks and visualization tools
What it is: A capability of a time series data storage system that exposes APIs and connectors so ML pipelines, dashboards, and notebooks can access and use chronological datasets with minimal preparation.
What it does:
- Serves aligned and cleaned sequences via SQL/REST/gRPC/streaming endpoints.
- Supports feature extraction through query-based transformations.
- Feeds visualization tools with real-time slices and aggregates.
- Integrates into ML orchestration frameworks using dedicated connectors.
Input:
- Requests from ML frameworks or visualization tools
- Feature extraction or visualization parameters
Output:
- ML-ready datasets for training and inference
- Visualizable time-series outputs for dashboards and notebooks
Looking for a trusted provider of ML development services? Don’t hesitate to reach out to Intelliarts.
How to choose the right time series database for your ML project
Selecting a TSDB is a decision that can greatly impact the performance and reliability of your ML pipelines. To help teams make the right choice, Intelliarts gathered practical, data-backed guidance based on real-world implementations across IoT, forecasting, anomaly detection, and telemetry pipelines.
Check the following key parameters to evaluate, why they matter, and the concrete performance metrics your TSDB should meet depending on your ML needs:
Data volume, velocity, and retention needs
Your incoming data rate and retention strategy influence ingestion speed, storage cost, and query performance.
Why it matters: TSDBs differ dramatically in performance. Some write around 200,000 datapoints per second, while others exceed 1 to 5 million per second.
How to evaluate:
- Estimate peak ingestion, for example, 100,000 points per second for sensor networks or more than 1 million per second for telemetry pipelines.
- Map required retention windows (from 30 days to 5 years).
What to do:
- If you expect more than 500,000 datapoints per second, choose a TSDB supporting at least 1 million sustained writes per second.
- If retention exceeds one year, ensure compression ratios of 20 to 40 times and automated rollups (1 second to 1 minute to 1 hour).
Real-time vs. historical analytics focus
Decide whether your ML workflows rely more on live signals or large historical datasets.
Why it matters: Query latency varies widely. Some TSDBs return real-time results in 5 to 20 milliseconds, while others respond in 200 to 500 milliseconds.
How to evaluate:
- Identify the query latency your ML tasks require, such as anomaly detection or long-window forecasting.
What to do:
- For real-time workloads, choose a TSDB with under 50 milliseconds of query latency and streaming ingestion.
- For historical analytics, ensure it can scan hundreds of millions of rows in under 500 milliseconds with indexed time filters.
Integration with your existing data stack and ML pipelines
Your TSDB must connect cleanly to your ETL processes, notebook environment, and model training workflows.
Why it matters: Weak integration adds minutes of overhead to pipelines that should run in seconds.
How to evaluate:
- Verify support for SQL, REST, and gRPC.
- Confirm Python client fetch latency under 200 milliseconds.
- Check batch export speed of 100 to 500 MB per second for training data.
What to do:
- If your ML workflow depends on notebooks or feature stores, choose a TSDB that can deliver aligned, ready-to-train batches of 10 to 50 million rows in 1 to 2 seconds.
Scalability and cost constraints
A future-proof TSDB must scale predictably without generating cost spikes.
Why it matters: Storage pricing varies. Some databases cost 0.10 to 0.20 dollars per GB per month, while others reach 1 to 5 dollars per GB at higher tiers.
How to evaluate:
- Check ingestion scaling, where each additional node adds 500,000 to 1 million writes per second.
- Compare cloud storage pricing and compression efficiency.
What to do:
- For growing pipelines, choose a TSDB that maintains 20 to 40 times compression, scales to more than 10 million writes per second, and uses hot, warm, and cold tiered storage to reduce long-term costs by 50 to 80 percent.
Important note: No TSDB, especially a proprietary one, can be ideal based on the listed and over parameters. If you are unsatisfied with the options available on the market, consider the development of a custom TSDB solution.
Final take
Time series databases provide high-quality chronological data that supports forecasting, anomaly detection, and predictive maintenance. Their architecture helps teams handle fast ingestion, structured storage, and efficient time-based queries. With the right TSDB, ML workflows become more reliable and cost-efficient. The choice depends on data volume, latency needs, and integration requirements. When selected carefully, a TSDB can improve performance, reduce overhead, and support long-term analytical growth.
Should you be looking for a trusted provider to drive your TSDB project, consider Intelliarts, an ML development company, as your best choice. We have over 25 years of experience in the market, more than 80 large projects under our belt, and a 90% customer return rate. With a majority of senior staff engineers in-house, we are ready, willing, and able to create your custom TSDB and make it work for your best ML project.
Custom ML Development
Our senior engineers are here to build your next TSDB project
Explore our service
FAQ
Is a time series database good for analytics?
A time series database is great for analytics because it handles high-volume, fast-arriving metrics efficiently. It supports quick aggregations and anomaly detection. Its optimized structure makes it easy to track patterns, seasonality, and trends, which improves dashboards, forecasting, and real-time operational insight.
How are time series useful in data analysis?
Time series help analysts understand how values change over time, and this reveals trends or anomalies that static snapshots often hide. I split the complex part here because sequential behaviour exposes long-term patterns or cycles. That is why storing time series data is essential for forecasting and optimization.
What is the main advantage of using a time series database?
The main advantage of a TSDB is performance. It is built for rapid ingest, compression, and time-based queries. This makes it far more efficient than general-purpose databases when analyzing metrics. It enables high-resolution monitoring, automatic rollups, retention control, and real-time insight.









