

As of 2024 and potentially beyond, Retrieval-augmented generation (RAG) models are gaining traction. As evidence, Databricks reports that 60% of their LLMs use RAG. And, since the global LLM market, valued at $4.35 billion, shows an extremely fast compound annual growth rate (CAGR) equal to 35.9%, using RAG seems more than beneficial.
In this post, you’ll learn basic concepts related to retrieval-augmented generation. Besides, you’ll find out how it works in relationship with LLMs, what tools are used to integrate RAG, and what the workflow of processing a user’s query looks like when there’s RAG technology involved.
What is retrieval-augmented generation and why do you need it?
Retrieval-Augmented generation or simply RAG is a generative AI framework that augments or simply updates and improves Large Language Models (LLMs) with relevant data from chosen sources.
RAG technique is primarily suited to Natural Language Processing (NLP) applications. RAG combines retrieval-based methods with generation-based models, leveraging the strengths of both approaches and putting them to use.
For a detailed comparison of AI models like Claude and ChatGPT, which complement RAG systems in enhancing text generation capabilities, check out our article on Claude vs. ChatGPT.
Here’s why developers widely used RAG with LLMs:
- Enhanced accuracy of LLMs’ predictions
- Usage of up-to-day information in real-time
- Higher-quality outputs that are both contextually accurate and creatively generated
- Better efficiency when working with high volumes of data
- Better capabilities for operating with highly customized responses
Using the RAG approach has no cons except for making the system more complex, and, therefore somewhat harder to develop and maintain.
How does RAG work in LLMs?
RAG utilizes pre-trained LLMs, which allows it to generate text. At the same time, the technology incorporates a retrieval mechanism that allows the model to access external knowledge sources. This way, RAG integrates retrieval into the generation processes.
For a detailed look at best practices and strategies for implementing RAG systems in enterprise environments, check out our article on enterprise RAG.
The knowledge base can be composed of any information-containing artifacts, including:
- Internal company wiki pages
- Files in GitHub
- Messages in collaboration tools
- Topics in product documentation, including long text blocks
- Text passages in databases supporting SQL queries
- Document stores with collections of files, like PDF legal contracts
- Customer support tickets in content management systems
As for the RAG’s retrieval mechanism, it operates by retrieving relevant texts from external sources, which are later used as inputs to the generative model. The latter synthesizes the information and produces coherent and contextually appropriate responses.
Here’s the complete two-step procedure for the model to learn how to select the best documents and generate appropriate responses based on them simultaneously:
Step 1: Document retrieval with DPR techniques
RAG frameworks start by exploiting the dense passage retrieval (DPR) techniques. DPR encodes both the input query and the external documents into dense vectors using a transformer-based model. Such dense vectors represent the query and the documents in a high-dimensional space. The model retrieves documents by calculating the cosine similarity between the query vector and document vectors, selecting the ones with the highest scores. This technique ensures the retrieval of documents that are semantically related to the query, even if there are no direct keyword matches.
Alternatively, a RAG system can function with more than just plain document chunks by integrating a graph database. This enables the system to capture the relationships between chunks and operate at various levels of granularity, enhancing the retrieval process.
Step 2: Generating responses with LLM
Once the relevant documents are retrieved, they are used to condition the response generation. This is accomplished with a model like GPT-4, which generates responses based on the input query and the retrieved documents. The documents act as extensions to the input, providing the model with additional context for more informed responses. Integrating DPR within the RAG framework improves the model’s ability to handle complex tasks that demand a deeper understanding of the subject matter.
Integrating DPR within the RAG framework enhances the model’s knowledge base, making it exceptionally adept at handling tasks that demand a profound comprehension of the subject matter.
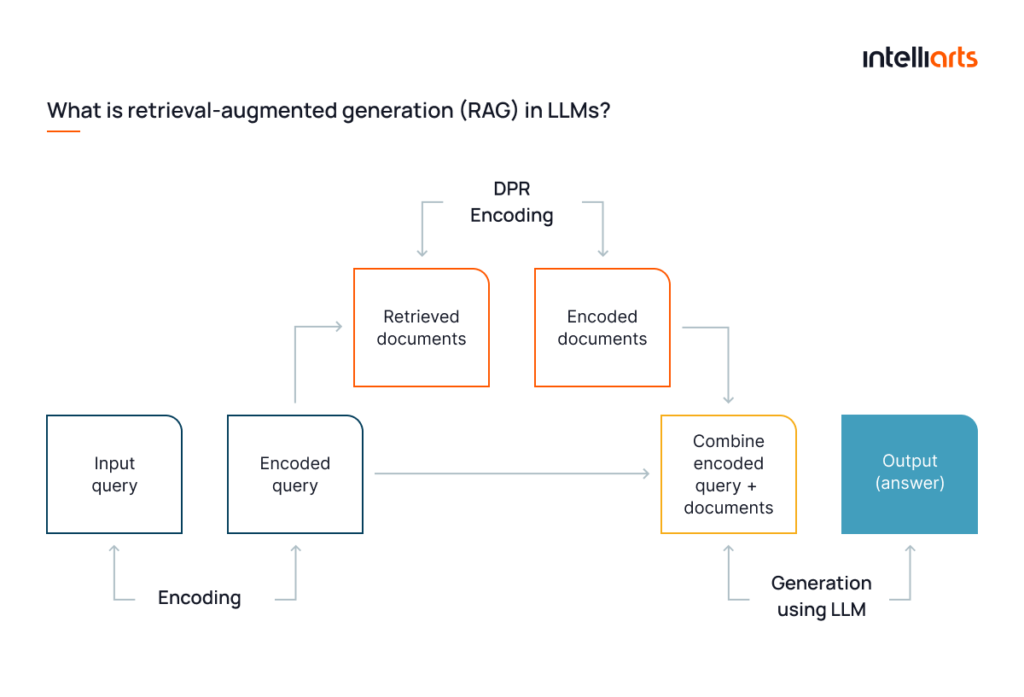
The RAG-LLM relationship in executing retrieval and generative functions
On the backend, RAGs execute retrieval and generative models in 5 key steps. Here’s the detailed procedure description:
#1 Sourcing
Sourcing from internal text documents and enterprise systems is the starting point of an RAG solution. Here, the unstructured and structured source data is searched and queried. The outcome of the sourcing stage is the pool of relevant information.
Pro tip: To ensure accurate and diverse data sourcing, it’s essential to maintain up-to-date metadata and minimize data redundancy.
Read also about generative AI in marketing.
#2 Pre-processing data for retrieval
It’s essential to organize multi-source data and metadata for real-time access, which includes integration and unification. Here are the possible types of data:
- Customer master data. Customer ID, name, contact information, and account information
- Transactional data. Service requests, purchases, payments, and invoices
- Interaction data. Emails, chats, and phone call transcripts
Depending on the use case, data may need to be arranged by other business entities, such as employees, products, or suppliers.
#3 Pre-processing documents for retrieval
Unstructured data, such as textual documents, must be divided into smaller, manageable pieces through chunking.
Chunking is the process of breaking down large pieces of unstructured data, such as textual documents, into smaller, more manageable units called “chunks.”
Textual chunks are then transformed into vectors for storage in a vector database, enabling efficient semantic search. This embedding process, using an LLM-based embedding model, links the embeddings back to the source, ensuring more accurate and meaningful responses.


#4 Protecting the data
Here, Role-Based Access Controls (RBAC) and Dynamic Data Masking are the primary protection measures.
RBAC is a security mechanism that restricts access to information based on the roles of individual users within an organization.
At the same time:
Dynamic data masking is a technique used to hide sensitive data in real-time, ensuring that unauthorized users see only obfuscated or anonymized information.
By using RBAC and dynamic data masking, as well as Privileged Access Management, a company ensures that sensitive customer information is protected and only accessible by authorized personnel. Thereby it complies with GDPR requirements for data minimization and access control and provides the required security level.
#5 Engineering the prompt from enterprise data
After enterprise application data is retrieved, the retrieval-augmented generation model generates an enriched prompt by building a “story” out of the retrieved 360-degree data.
Ongoing prompt engineering, ideally aided by machine learning models and advanced chain-of-thought prompting techniques, enhances the prompt’s quality. This might involve reflecting on the data to determine additional information needs or checking if the user has finished the conversation.
Bonus Example
Let’s review a more practical instance, revealing how the RAG with LLM relationship works on user queries. The RAG architecture diagram below illustrates the retrieval-augmented generation framework and data flow from the user prompt to response:
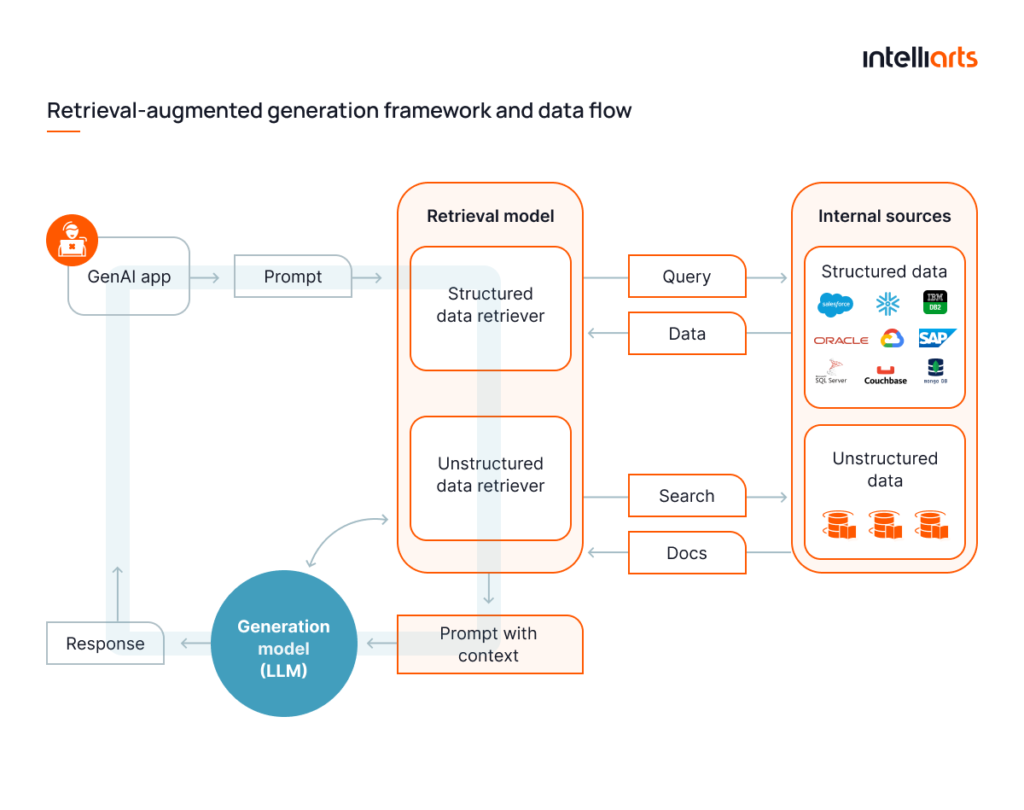
- The user enters a prompt.
- The retrieval model accesses the company’s internal sources for structured data and unstructured documents.
- The retrieval model selects parts of documents that will help to answer user prompts as contextual information.
- The retrieval model enriches the user’s prompt with additional contextual information.
- The enriched prompt is passed to the generation model (LLM).
- The LLM uses the augmented prompt to generate a more accurate and relevant response.
- The response is provided to the user.
Integrating RAG with language models
Here’s the basic, step-by-step procedure for integrating RAG with any of the top large language models:
1. Setup prerequisites
Hugging Face Account: Sign up for a free Hugging Face account to access embedding models and download the Llama-2 model. Recommended options and ways of their usage are:
- Llama-2: Request access to Meta’s Llama-2 model via Meta’s website for integration.
- LlamaIndex: Use this framework to load data and feed it into Llama-2.
- Chroma: Employ this embedding database for fast vector similarity search and retrieval to store the index.
2. Install required libraries
Install the necessary libraries for the project.
3. Import necessary modules
Import the required modules from the libraries to set up vector indexing, embeddings, storage functionalities, and other computations.
4. Provide context to the model
Load the data into the model. For this demonstration, a PDF research paper is used. However, other data sources like Arxiv Papers Loader can also be used.
5. Download and configure Llama-2
Set up an account with Meta and have your access token ready. Configure the model to fit into constrained memory environments, such as Google Colab, by using 4-bit quantization.
6. Initialize the language model
Initialize the Llama-2 model with the necessary configurations, including the model name, tokenizer name, query wrapper prompt, and quantization settings.
7. Compare outputs without context
Test the model by asking questions without providing any additional context to see how it responds and identify hallucinations.
8. Create a ChromaDB client and collection
Set up a client to interact with the ChromaDB database and create a new collection to hold the vector index.
9. Initialize the embedding model
Set up the HuggingFaceEmbedding class with a pre-trained model for embedding the text into vectors.
10. Index-embedded document vectors
Set up the vector store and use it to index the embedded document vectors, allowing quick retrieval of relevant passages for a given query.
11. Establish a summary index
Create a SummaryIndex to enable the model to summarize the data efficiently and retrieve pertinent information.
12. Query with indexed data
Ask the model the same question, this time using the indexed data to provide relevant context and observe the improved response quality.
13. Enable interactive conversations
Set up a chat engine to have a back-and-forth conversation with the model about the content of the PDF file and ask follow-up questions to support more productive and natural interactions.
As a result, you should obtain an instrument capable of answering user queries with data that is reinforced with additional information from the database in real-time.
Key tools for integrating RAG with language models
You can see the comparison of the key tools for integrating RAG in the table below:
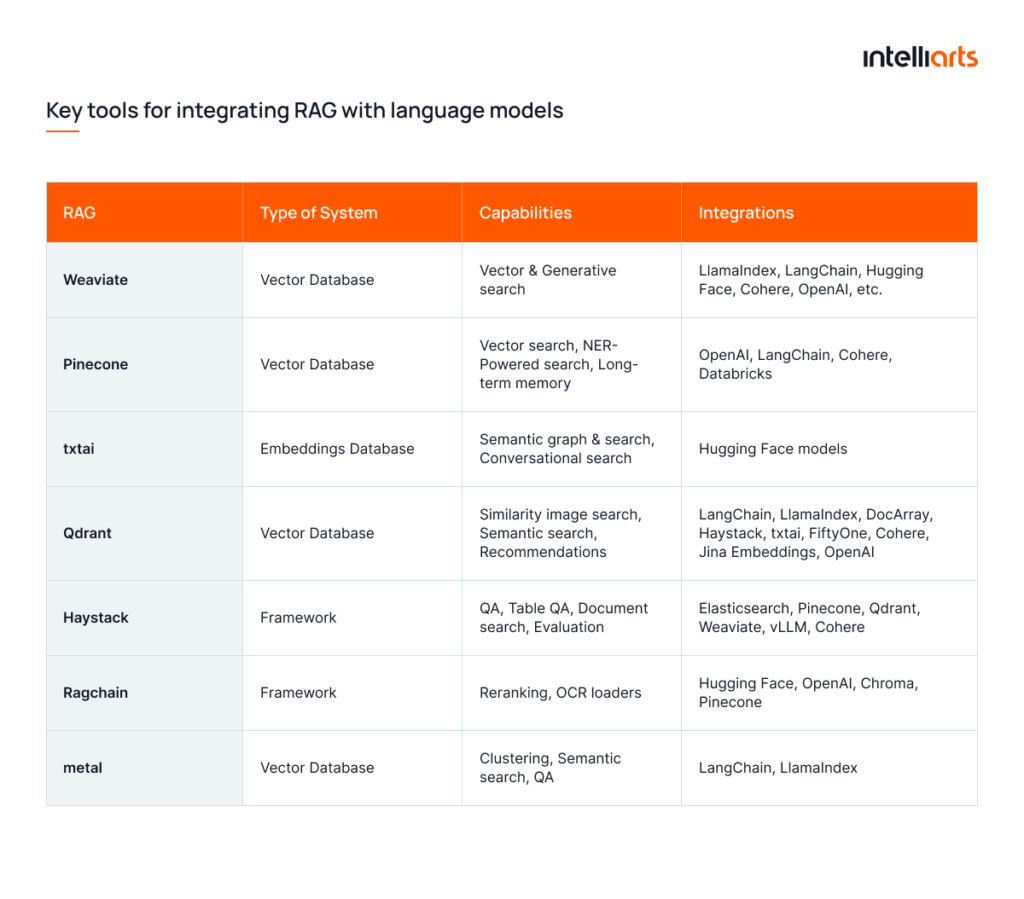
Here are the Gitgub repositories for each of the provided tools:
- Weaviate repository
- Pinecone repository
- Txtai repository
- Qdrant repository
- Haystack repository
- Ragchain repository
- Metal repository
Intelliarts experience with retrieval augmented generation language models
Data extraction chatbot development using ChatGPT
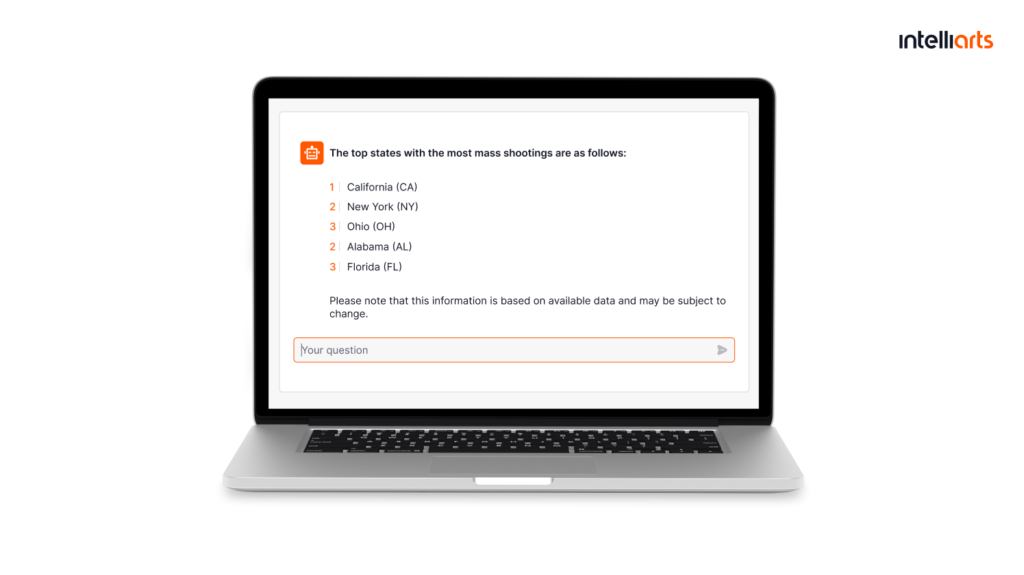
To assist the customer, the Intelliarts team built a chatbot using the GPT-4 model reinforced with the RAG model specifically for empowering the report requests. The chatbot was trained on the customer’s data. It can carry on a conversation exclusively about gun safety and related topics. It also can provide references as additional information.
The end solution which is custom and well-tailored to the customer’s workflow and content topics offers better productivity, automation, streamlined decision making, and ease of use.
Discover more about the chatbot development case study.
AI assistant to help students pass the cybersecurity course
The Intelliarts’ customer, who is a provider of cybersecurity training, reached out to Intelliarts with the request to create an AI agent. The solution was intended to help analyze students’ work in virtual environments and provide recommendations.
As a solution, the Intelliarts team provided recommendations regarding data collection. We researched and consulted the company on building an AI assistant by combining a classification ML approach and an LLM with an RAG model. Our team completed the discovery phase and built the PoC proved to perform the intended tasks. Now we’re moving to the full-scale solution implementation.
As for business outcomes, the Intelliarts team proved the feasibility of such an AI agent and provided the customer with recommendations for the next project steps, including data pipeline and data type requirements.
Discover more about the AI assistant development case study.
Final take
RAG enhances the capabilities of LLMs by combining retrieval-based methods with generative models. This innovative approach provides accurate, contextually rich responses and supports high data volumes. Businesses adopting RAG can achieve better decision-making, efficiency, and customer satisfaction.
Should you need RAG-based solution development or another AI/ ML assistance, don’t hesitate to reach out to the Intelliarts team. With more than 24 years in the market and hundreds of completed projects under our belt, we are ready, willing, and able to address your needs with flying colors.
FAQ
1. Is RAG different from generative AI?
Yes, RAG models integrate retrieval-augmented generation with generative AI, combining external information retrieval with language generation for more accurate and contextually rich responses.
2. How does RAG differ from traditional generative models?
Traditional generative models rely solely on pre-trained data, while retrieval-augmented language models enhance responses by incorporating real-time information from external sources.
3. How does the retrieval model work?
The retrieval model in retrieval-augmented large language models searches structured and unstructured data, enriching the user’s prompt with relevant contextual information.









